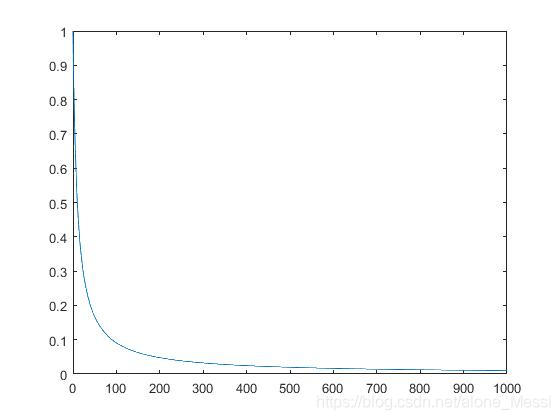
由于学术需要,这段时间再训练一个分类器,但其效果不太好,loss下降不明显。便考虑是不是学习率的问题,由于使用的是SGD,其中一个参数为decay,借鉴别人的参设默认值,decay 一般设为1x10-4 .我怀疑是训练过程种学习率太大,于是想找到SGD优化器种学习率衰减的公式,但能力有限,读代码没读懂,就在网上找,也没找到。 例如当decay = 0.1时 要到100个iteration时才能将为原来的0.1左右 当decay = 0.01 时 这样衰减效果就明显多了,1000个iteration时即可到达初始学习率的0.1左右 SGD学习率衰减,过于简单。可以尝试其他优化器或者自定义学习率。由于能力有限,后面再解决这些问题,如有错误,欢迎指正。共同学习,共同进步。
最后再Google上找到了,帖子的连接如下:
https://machinelearningmastery.com/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
计算的公式如下:
initial_rate为初始优化器时的学习率,decay为衰减参数,iteration为迭代次数
但这个衰减的公式过于简单,再前期衰减的很快,后期几乎不衰减。
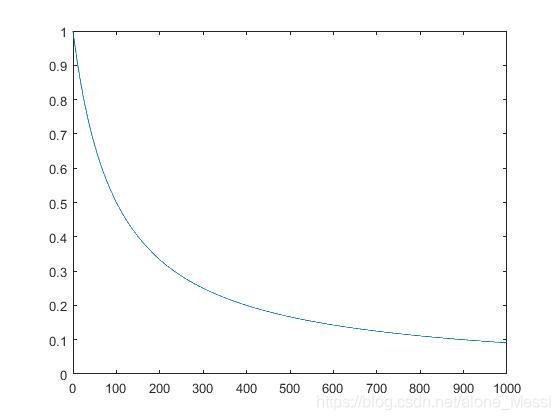
而且SGD学习率是在同一个epoch,不同iteration之间的。想要再不同epoch中衰减可以使用scheduler。
创客课程开发的每个主题课程需要基于现实情景,设置学习探究任务,通过问题研究、任务...
创客空间建设 能够给人们分享各种乐趣,通过电脑,技术,科学,艺术结合,设计创造一...
在了解创客教育之前,我们首先了解下何为创客。创客是一群喜欢或享受创新的人。创客跨...
STEAM教育是对传统教育的提升,它是基于自然学校方式的功能性框架,可以适合各类...