实际工程代码基本是清晰第一,效率第二的,所以下面大多数奇技淫巧适用的场景大部分是ACM之类的 1.超快速读入 现在快速读入已经不算黑科技了吧,下面这个读入在hdu上面速度比快速读入快 const int BUFSIZE=120<<20; char Buf[BUFSIZE+1],*buf=Buf; template<class T> inline void scan(T&a){ for (a=0;*buf<'0'||*buf>'9';buf++); while (*buf>='0'&&*buf<='9'){a=a*10+(*buf-'0');buf++; } } fread(Buf,1,BUFSIZE,stdin); 2.扩栈,系统栈在windows下有限,爆了怎么办? #pragma comment(linker, "/STACK:102400000,102400000") 3.vim写代码用到c++11的特性老是要编译的时候加上-std=c++11,直接在程序上加: #pragma GCC diagnostic error "-std=c++11" 4.同样类型的黑科技,程序里面开O3优化__attribute__((optimize("-O3"))) 5.09年骆可强论文中提到的各种黑科技: 为了消除分支预测,可以把绝对值写成: max函数写成: 计算两个int的平均数(也是整数),x,y两数相加可能会溢出,可以写成: 为了使cache命中率更高,尽量避免2的幂次方长度的数组 6.c/c++里大括号{ }可以和<% %>互换..........并不知道这有什么意义 7.在某些场合使用以下代码估计很多人已经熟悉了,但第一次看到下面代码还是费解了半天 8.针对OJ的,某些OJ的long long是%lld有些是%I64d,是不是还在一个一个改? 可以这样巧妙的利用宏: 比如输出就可以printf("output: "LLD"\
", x); 然后就可以只改一个了 9.两个long long 相乘然后mod p,相乘以后可能会溢出,古有快速幂,现有快速乘法,这个的普及程度现在基本上也不算黑科技了 我做的是锂电池BMS系统中的电池容量算法和主控IC function,而且很多都是出口的。这个IC是和电芯组合成一起作为电池Pack装到手机/笔记本里的,所以在整个电池使用的三五年中程序必须正常运行不出错。因为锂电池容量算法特别复杂,稍有参数、代码错误表现的就是iPhone或笔记本电脑立即关机。在笔电上还好说,因为有对IC的DFU/IAP支持,之后升级/维护方便;但在手机上并无此功能,如果错了就可能面临出口产品的退货/召回、工厂IC的code重烧等,非常麻烦。 因为主IC还是C51平台、在Keil上编程,调试或排查极其不便。特别涉及到容量算法,必须用锂电池去充放电实测来检验算法的精度与异常处理,通常调一次参数就需要高温\\低温\\常温+轻载\\重载\\中载组合测试,需要一周时间。效率极低,而且出错概率大。仅靠经验、拼人品显然是不可能做下去的。 之前采用了matlab进行仿真,但由于代码和KeilC的语法完全不同,故达不到代码debug的效果。为此,专门在知乎上请教了轮子哥和赵姐夫,开始搭建C++仿真。在Visual Studio中采用C++模拟C51中的硬件器件运行结果,达到KeilC和C++代码每行都完全兼容,运行结果也完全一致。举个最简单的离子: C51是8bit CPU,每次加法若溢出后,会置位PSW标志位[CY]为1.在程序中经常会用if(CY)判定是否溢出。在C++仿真中便采用了运算符重载的办法进行了模拟。将特定的加减法转换为自定义类型的加法,这样程序跑到重载函数中便可模拟8bit溢出的情况。 仿真将电池充放电log数据吃进去之后,实际模拟出运行的效果,使原先一周的验证时间缩短到了半小时,现在锂电池算法的效果已经非常好了,逼近世界No.1的TI。 在工作过程中,我一个嵌入式工程师,专门学了好多C++和C#的东西,自己的进步很大。同时学习了STM32的官方C库,收获了很多。在之后诸如TWI、HDQ、E2ROM、USB等等其他扩展功能上也贯彻了严密细致的精神,程序现在伴着IC每月1M+的出货量稳稳的运行着。特别感谢知乎,让我认识了那么多的软件大神,特别感谢轮子哥和赵姐夫在答案中的指点! 谢邀。 利益相关:利益相关 最近看到了好多「华为方舟编译器」的帖子, 华为好棒,加油。 不过目前支付宝并未使用华为方舟编译器。 知道你们老吐槽说支付宝启动慢, 虽然能找出很多理由来解释, 比如支付宝通常不会常驻后台, 比如支付宝对安全更重视,启动时需要更仔细的检查等等。 但慢确实体验不好,再多的理由也没用。 所以近几年,我们悄悄启动了一个「秒开」的大项目。 这个事挺难的。 虽然我们有很多用户是用iPhone,用华为, 但还有更多的用户在用各种安卓系统 我们希望所有的用户,不管用什么手机, 不管是不是常驻后台,都能更快的享受服务。 这个难度可想而知。 一直没有官宣, 是因为我们觉得,虽然现在比以前快了不少, 但还没有达到我们的预期, 我们希望能让更多的人在使用时能「WOW」一下: 「启动秒开」、「扫码秒扫」、「切换秒滑」…… 很开心已经有一些用户能直观感受到这种差别了。 既然被问到了, 还是说一下「秒开」背后的我们攻坚的技术,包括 来都来了, 要是你是这方面的技术专家, 想让自己的技术造福全球超10亿用户, 来份简历呗~ 第三年的回答 答主接触ck三年了,下面的回答是不同时期的感受. 对ck的认识之前经历了下面几个阶段: 1. 未识ck 未看过代码,听闻性能很厉害;内心觉得太神奇了,太不可思议了. 让人惊艳的软件,往往存在很多并不懂得内在原理但是认识却根深蒂固的粉丝群体,多数人受以讹传讹myth的影响,会逐渐形成通识,影响更多人. 2. 初时ck 被惊人的抽象泄露的细节深深地震撼和折服. 3. 熟识ck 提升性能有几种方法: 抽象泄露是提升执行器计算能力的方法,只要其他人借鉴和大力推行这种方法,把抽象泄露做得更加普及和彻底,就可以做出更快的计算引擎. 这种抽象泄露是永无止境,一个问题优化,往往可以带出10个新的优化点,研发干活速度赶不上优化TODO list的增长速度, 在研发的执行层面,需要魄力和强大的执行力不停地持续优化. 4. 对抽象泄露从推崇转入疲劳 这是一种细节堆砌,使代码的可维护性越来越糟糕,面向用户的沟通成本越来越高, 技术门槛很低,对软件架构能力要求不高的,迭代越来越吃力的,毫无创新的方法. 应该早日摆脱这种方法,寻求更好的创新的软件构建方法. 第二年的回答 这个回答是一年半之前的回答, 现在补充一点内容. 现在大家都知道olap的执行引擎需要搞MPP, 向量化和多核scale调度. 向量化我感受最深刻的一点是,很多olap开发者基本上知道codegen+编译器的autovectorization功能,包括很多不在一线搞olap引擎研发的,单纯从技术insight角度出发的人,都知道这点. 但是,个人浅见是codegen解决一些表达式运算(尤其是算数运算,cast表达式和部分谓词计算)是OK的, 但是到了复杂的表达式,算子和函数 , 就没法搞codegen或者即使搞codegen, 对性能的提升也有限. 那么怎么提升计算的性能呢? CK其实提供了一种可靠的,可持续优化提升性能的,根本的人肉的工程方法-抽象泄露, 即不断地给函数或者算子的局部逻辑增加更多的变种实现, 以提升在特定情形下的性能. 比如: 能不能举个例子呢? 比如arrow数据类型转换starrocks的内部数据类型, 最简单,抽象地最好方式,就是将arrow的数据转换为string,然后把string转换为starrocks类型. 但是要做到高效, 就需要分蘖出各种情形的处理函数了. 我特别喜欢把这种抽象泄露称之为分蘖, 分蘖就是不断分叉分叉再分叉,分蘖是对这种工程方法最佳最形象的汉语翻译. 比如下面这个代码: 但从更长远技术远景看, 编译优化才是未来. 第一年的回答 一年半之前的回答在这儿. 评论区有朋友问到,ck的字符串查找,ppt找到了. 探究一项技术,应该具体问题具体分析. 谈几件事,说明这个问题,我研究过ck的decimal计算和string函数. 其实数据库发展到现在,祖师爷已经把理论写下来,公开给大家用,很多业界案例也可获取. 系统和系统的差别其实是代码细节,是品控. 品控做到一定程度后,再提高一点,复杂度和时间都是翻倍增长的. 开发者愿不愿意做呢? 老板愿不愿意投入呢?这里面砖活很多的,写micro benchmark,微调代码,反复测. 看汇编,改写汇编. 除非特别感兴趣,不然的话,搞个业务系统,妥妥升职不香吗? 所谓:夫夷以近,则游者众,险以远,则至者少. 有志有力,不随以止,不随以怠,至于幽暗昏惑,有物以相之,或可至人迹罕至之所,览非常之观. 同样是对物质的认识,这个东西可以粗糙到阴阳五行,精细到分子原子电子质子夸克,还有弦啊膜啊之类. 看病也是一样,粗糙到跳大神,切脉吃草药,精细到拍片子吃靶向药,基因改造. 所以品控和精细化,才产生了辨识度. 当然ck不是没有缺点,也有: 1.catalog缺乏, 2.数据复制晦涩, 3.建分布式表麻烦, 4.模板使用嵌套层次太深,我最近打算把guard编程的思想,翻译成英文,寄给他们老大,把这块代码搞扁平一点. 然而ck代码的incremental refine做得很好. 难读但是好改. 缺的东西,正好云原生方面的工作可以添加上. 这些微乎微乎,至于无形,神乎神乎,至于无声. 这些东西掌握了,也只能在小圈子分享. 几KB是比较小的单位,在我的经验范围内感觉没什么必要,怎么也得到几MB才有必要。 但毫秒…对计算机来说真的是很大的单位了…一毫秒,可以做很多很多很多事情。跑一个优化过的神经网络,用普普通通的硬件,小的一点几毫秒,中等的几毫秒。一个if语句,耗时是以纳秒记的… 做过的很多项目,有一整个周期一毫秒的,也有十毫秒的。那个一毫秒的项目,只要出现个超过三百微秒的波动,整个系统就挂了,你这一言不合就是提升几毫秒…即便是十毫秒一个周期的项目,那几毫秒也是不得了的成就了… 这种题目,随机误差都比你要测的数据显著了,能测出什么鬼? 最基本的,“两个链表”请一定要确定是“两个”! 现在的CPU,访存一次的时间消耗都超过几百条指令了;你搞这么小的数据,还在同一个链表上测;第一次测数据还没加载进内存,动不动cache miss;第二次测,数据大部分在内存(如果数据量大可能淘汰一些),少几次cache miss什么都有了。 真想玩,改程序,不要就这么测一次,而是两个都先跑一次,扔掉结果;然后T1T2T1T2的反复交错跑,跑上至少十次,求平均值,看看结果如何。 另一些问题定位思路: 1、把链表访问去掉,改成自增一个volatile变量,排除寻址/cache的干扰,看看究竟相差多少; 2、把链表改成数组/二叉树 3、把链表改成函数调用 简单说就是把一个个影响因素独立出来,各自分析。不要越搞不明白添加越多代码…… 妈蛋我millies micros到底哪个是毫秒哪个是微秒。。。 我们最近对某个函数进行改动,用到了一个四舍五入的调用不够优化,导致这个函数慢了大概两个micro。 这个函数每次市场有数据过来,每个货币对都会被调用20到40来次,也就是这个问题会耽误到40到80micro。 市场忙的时候,大概每个millies会发过来四五个数据包,每个包大概5到15个货币对不等。 因为市场数据处理很多时候不能并行化,所以一旦耗费的时间超过两三百micro,就会造成拥堵。也就是说,在第一个数据包处理完以后系统就可能产生拥堵。 来在市场忙碌的极端情况下,这种拥堵会系统在处理这个millies内的最后一个数据包时已经是4、5个millies以后的事儿了。然后忙碌的市场持续个两三百millies就会造成秒级拥堵,如果继续持续忙碌半分钟,就能造成分钟级的理论延迟。 然后最近的外汇市场正好就非常忙碌。微观情况下持续几百millies的繁忙会非常常见,持续几秒、几十的高频数据也不是不可能。 任何一家大型做市商在忙碌的市场下慢个几秒钟就足够造成几万甚至几十万美元的亏损了,更何况接近分钟级的延迟。。。 当然增加这两个Micro的改动在函数上线前被揪了出来,没有造成什么损失。 分享一个知名开源项目workflow中构建dag图非常好用的语法糖用法。 先举个栗子 DAG中的任务,可以是workflow框架的任何一种任务。 本示例中,我们创建了一个timer任务,两个http任务,以及一个go任务。 它们之间的依赖关系如下: 完整代码: workflow顾名思义,是工作流,具有多种不同类型的task,比如timer task(定时器任务),go task(计算型任务), http task,mysql task,redis task 等等。能很方便的将任务以串并联的方式组合在一起进行调度运行。在大型工程中尤为常见,在每一个模块中都会有很长的一个运行流程,根据各个阶段职责不同,划分为一个个的op,串成一个复杂的图运行,这样就能将一个复杂的模块细粒度化,方便开发。 workflow提供了一种非常清晰的方式, 通过非常形象的'-->'运算符,建立节点的依赖关系: 这样我们就建立起了上述结构的DAG图啦。 除 接下来直接运行graph,或者把graph放入任务流中就可以运行啦,和一般的任务没有区别。 他的实现原理特别简单,就是重载了 operator 自从steam deck可以不限量购买了以后,我就动了买回来试一试的心思。毕竟我对掌上游戏设备有特殊的情怀,之前还入过gpd这种坑。但在购买,使用,改装的一系列过程中,最大的感受却是折腾,十分的折腾。 你如果把它当做像switch一样的纯掌机,登入steam账号就能够自由地玩你库里所有的游戏,那你注定是要失望。但如果你希望有一个拓展性强的类似移动pc的专业掌上游戏设备,那steam deck的确是有很多拓展空间的。那这里我就按照时间顺序,一点一点分享一下我对steam deck的折腾体验吧。 1.购买 虽然很多人说steam deck原价很便宜,2000多块的机子之前在国内被JS卖到七八千简直是暴利。但现阶段steam deck可以充足购买的时候,个人原价获得的海淘渠道实际上是不降反升的。我应该是踩着最贵的时间节点购买的了,最早卡图代充可以做到500以下兑100美元的,而我购买时尽管用的卡图代充,当时的价格也涨到了590兑100美元的高价(现在差不多降回570了,也不便宜),再加上中环卡转运等一系列因素,我选的最贵也必税的fedex渠道,好处是两周左右就到手了,坏处就是也差不多花了800块。所以如果朋友们看到国内现货在3500左右真的可以冲了,自己买也真差不多就这个价,2000元的价位一去不复返了。。。 购买过程中也是经历了很多的折腾过程,但如果你真的想买,按着网上的攻略来基本上没什么问题。这里建议大家找海淘攻略的时候注意一下时间,因为整个海淘局势是不断变化的,10月以前的中环转运攻略很可能让你卡仓库卡一个多月。你找最近的fedex转运攻略,照着一个一个填,基本不会有错。 注册美区账号,卡图代充,注册转中,填写个人资料,按转运仓地址下单,期间关注物流情况,及时网上报关,fedex的税是当面收的,我特地从公司跑回家来缴税(早知道收货地址写公司了)。从下单到入手差不多16天吧,机器2358+转运404+税390,64g版到手花了3152,然而折腾才刚刚开始。。。 2.机器体验 大,重,塑料感,这是在购买之前就做好心理准备的。但我没有预料到的是这个掌机的人体工学设计还不错,两个手柄的握把拿在手中更为舒适,放在桌上的时候也可以支起机器,不会挡住风扇。不过L1,R1的两个肩键却感觉很难按,背键暂时也没有发觉有使用的机会,有待后续进一步体验。 PS:说真的掌机界最没有人体工学设计的就是任天堂了!switch oled,3dsll,那么大还做得方方正正的都是什么玩意(我知道是为了拆分手柄等市场原因啦,但真的很想吐槽)。 Steam OS初见的感觉还是很好的,尤其是第一次进入的时候,通过屏幕上几个简单的指示标出了开关,音量,tf接口的位置。新增的steam键和“。。。”键里面功能也很全,基本上所有你想要调整的设置都能够轻松找到。 但是接下来的体验就没那么好了。首先是虽然国内的steam下载速度仍然很快,但是steam deck在下载的过程中很多其它的操作会莫名其妙地卡死,包括启动游戏,切换桌面模式等,所以后来在下载游戏的时候我都不敢做什么操作,只能静静地等它下载。这件事真的很蠢。。。 第二是完美适配steam deck的游戏没有想象的多,虽然很多朋友说不完美适配的也可以玩,但大多数卡启动器的游戏就很让人生气,比如育碧游戏卡育碧登录,ea游戏卡ea登录,玩老游戏生化危机5还会卡windowslive登录。另外,有些标绿标的游戏居然也进不去,比如dmc鬼泣,明明写的是完美适配steam deck,就是进不去,不知道为啥(重装系统后进去了)。当然,卡登入可以加速器,改host,换启动器,网上都有攻略。甚至很多显示不能适配的游戏也能够进得去,但这免不了又是无穷无尽的折腾。。。 每当机器因为不知道什么原因卡住的时候,最好的方法就是重启。有时候多重启几遍,不能玩的游戏也能玩了。这时候我才真正感受到这台机器终究是一台掌上pc,重启解千愁啊。。。 3.改装 说是改装,其实就是所有64g steam deck掌机的必经之路:换硬盘了。本来10月份放入购物车的sn740价格599,想看看双十一有没有降价,结果一路上涨,现在都要699了。。。是真的有这么多人在最近买机器是吗。。。 换硬盘其实本身很简单,就算手残如我,照着视频教程一步步做就是了。这里强烈建议大家多花20几块钱再买一套steam deck拆机工具。网上好多视频教程说螺丝滑丝了都是用硬盘附送的螺丝刀的原因,用适配的最小号的螺丝刀拆一点也不会有这个问题。另外还有将后壳拿下来的时候,大家请在心中默念,大力出奇迹。。。 然而没想到的是,换完硬盘之后,才又是折腾的开始。首先是装steam os系统,我按照网上的教程做了系统盘,却卡了半个小时怎么也进不去,后来才发现原来这机器对系统盘的接口速度也有要求,得换上usb3.0的高速U盘才行,得,又重做了两个系统盘才进去。所以大家一定要把自己手上最好的U盘拿来给steam deck上供呀! 另外装上系统了,又卡在了steamos更新和登陆。虽然是我刚拿到机器的时候没用加速器也进去了,不知道为何这次得开了加速器才能登进去。国内用steam系统就是这样,各位朋友还是有魔法的开魔法,有加速的开加速吧。 终于折腾进了“新机器”,这回我换上1T的ssd加上512的tf卡,终于可以想下什么游戏就下什么游戏了。但下的游戏多了,折腾的事也变得更多了。。。 4.进阶 steam deck可以做的是其实很多很多,包括运行epic、gog等平台的游戏,运行模拟器,甚至是运行学习版游戏。但想要真的一一体验到这些内容,又免不了是一番折腾。 就拿安装epic启动器举例,现在网上有直接安装epic启动器,或者使用steam deck网上商店的heroic app来启动。heroic应该是最好的方法,可以直接登陆epic和gog平台,并且自带兼容层,似乎是折腾最小的方案了。但现在的问题是,steam deck的网上商店打不开。。。好吧,网上商店打不开是因为加速器的问题,反复开关加速器,终于把app和兼容层下载下来,在桌面系统里把这个APP添加到steam库里,再回到steamos里打开。epic里面领了不少免费游戏,其中最值得的就是给他爱5啦,好不容易下载下来,卡在R星启动器界面,又是一通输入账号密码才进去。。。进游戏之后还要自己调试分辨率,设置,才终于能够流畅运行。。。这还是其中最顺利的一次了,遇到找不到兼容层的,或是卡启动器的,就算各种调试也进不去。。 在这里,再建议大家准备好拓展坞,我的拓展坞还在路上,现在只有一个蓝牙鼠标。折腾过程中因为要反复输入指令,输入账号密码,并且steam deck那么点点大的触屏,用手指点击根本点不到,鼠标键盘可以说是必须的。虽然蓝牙鼠标键盘会方便一点,但是因为机器反复重启,蓝牙鼠标也经常断连。实在是很令人烦躁。 现在我搞定epic了,有空会再试试模拟器,又免不了是一番折腾。 5.成就感 怎么说呢,steam库上的游戏其实大多数都玩过了,可能现在折腾机器比玩游戏本身更有趣,好不容易把一个不能玩的游戏进入进去了,成就感大大提升。至于日后你是不是真的会在steam deck上通关这个游戏,已经不重要了。我把之前卡ea启动器的星球大战绝地武士给搞进去了,epic上的给他爱5也能60帧游玩了,这部分还是挺开心的。但是我的steep还卡在育碧启动器,蝙蝠侠阿卡姆骑士看别人都能玩就我进不去,就很气。。。 steam deck的系统和兼容层很玄学,而且上网看一下,每个人遇到的问题还都不一样,很多视频攻略给了大致的教程,但并不能完全解决你游戏中出现的所有问题。所以,可能玩的过程中,还要学会放弃吧。。。 ClickHouse 是 OLAP(Online analytical processing)数据库,以速度见长[1]。ClickHouse 为什么能这么快?有两点原因[2]: 但是,数据库设计再优越也拯救不了错误的使用方式,本文以 MergeTree 引擎家族为例讲解如何对查询优化。 SQL 的解析优化和编译原理息息相关,本节将包含大量编译原理和代码细节,属扩展知识。 ClickHouse 拿到需要执行的 SQL,首先需要将 String 格式的字符串解析为它能理解的数据结构,也就是 AST 和执行计划。构造 AST 部分代码如下所示: 值得一提的是,解析 SQL 生成语法树这是编译原理中词法分析和语法分析部分覆盖的事情。词法分析只是简单拆解数据流为一个个 token,而语法分析分为自顶向下和自底向上两种方式,常见的语法分析方式也分为手写语法分析(往往是自顶向下的有限状态机,递归下降分析)和语法分析工具(往往是自底向上,如 Flex、Yacc/Bison 等)。 手写语法分析比起语法分析工具有几个优势(当然要写得好的情况): ClickHouse 解析 SQL 的函数如下所示: 可以看到先将 SQL 字符串拆解为 token 流(词法分析),再调用 可以发现 ClickHouse 将 Query 分为了 18 种类型(截止 2022-11-12 日),每种 Query 都有自己的 Parser,通过关键词匹配构造 AST 上的节点,最终生成语法树。递归下降部分超纲了,这里就不铺开讲。 经过语法分析后生成的 AST 并不是执行最优解,ClickHouse 包含大量基于规则的优化(rule based optimization),每个 Query 会遍历一遍优化规则,将满足的情况进行不改变查询语义地重写。 每一种 Query 类型都有对应的 Interpreter,后文都以 Select 查询举例,代码如下: 在 是否初始化 settings 优化 with 优化 joins 谓词下推将 where 下推到 prewhere 是否要再次优化检查 storage 权限生成 analysis_result 和 result_header 其中 可以看到: 索引是 ClickHouse 快速查询最重要的一环,分为主键索引(sparse indexes)和跳表索引(data skipping indexes)。在执行查询时,索引命中顺序如下图所示: Partition Key MinMax IndexPartitionPrimary Key Sparse IndexData Skipping Indexes 详见代码: 值得注意的是,主键的 sparse index 使用二分查找直接缩小范围到所需要的 parts,而跳表索引就需要在选出来的 parts 里,每 n 个(用户自定义)granules 就需要比较 n 次。 最佳实践: partition by 需要一个可以转为时间的列,比如 Datatime、Date 或者时间戳,而如果 primary key 中也有时间字段,可以使用同一个字段避免查询时需要同时指定两个时间字段。比如:指定为数据处理时间。 首先要辨析 part 和 partition 的区别,ClickHouse 应用层面定义了 partition,用户指定 partition by 关键词设置不同的 partition,但是 partition 只是逻辑分区。真正存储到磁盘时按 part 来存储,每一个 part 一个文件夹,里面存储不同字段的 当查询的 WHERE 带有 partition key 时,首先会比较每一个 part 的 minmax 索引过滤不相关 parts。之后再根据 PARTITION BY 定义的规则过滤不相关 partition。 可是 partition 不是越小越好。 partitioning 并不会加速查询(有主键存在),过小的 partition 反而会导致大量的 parts 无法合并(MergeTree 引擎家族会在后台不断合并 parts),因为属于不同 partition 的 parts 无法合并。[5] 最佳实践[6]: 主键是 ClickHouse 最重要的索引,没有之一。好的主键应该能有效排除大量无关的数据 granules,减少磁盘读取的字节数。 先讲几个主键的背景知识: 主键的选择应该尽可能考虑周全,因为主键是无法修改的,只能建新表后数据迁移。 最佳实践[12](针对(Replicated)MergeTree 引擎): 最后一步是跳表索引,这个没有太多可以讲的地方,和其他数据库相同,跳表索引用于尽量减少读取的行数。具体参看官方文档。 配置优化分为两部分,全局配置优化和 MergeTree 表配置优化。 参看Altinity选择性配置优化项。 这里写三个推荐的配置: 除了全局配置,MergeTree 引擎家族每张表也有自己的配置项。[13] 推荐设置如下配置: 除了索引、分区和配置外,还有表字段可以优化。接下来将讲述 Schema 类型、CODEC 和缓存三个方面。 注意,尽量避免使用 Null,在 ClickHouse 中 Null 会用一个单独 Null masks 文件存储哪些行为 Null[14],因此读取某个普通字段只需要 使用 ClickHouse 存储时,一般用户都会创建大宽表,包含大量数值、字符串类型的字段。这里提及两种 Schema 类型[16],没有哪个更优越,由读者执行评估业务适合哪一种。 这是我们主表正在使用的类型,将可能用到的字段预留平铺,除了一系列基础字段外,增加大量 优点: 缺点: 这是我们 ctree 功能正在使用的类型。将业务字段塞入嵌套数据类型中,比如 array、nested struct 和 map。后文以 array 举例: 优点: 缺点: 关于 Schema 设计这里,读者可以考虑 28 原则,理论上 80%查询只会用到 20%的业务字段,因此可以将使用频率高的业务字段平铺,将使用频率低的字段放入嵌套结构中。 CODEC 分为压缩算法 CODEC、存储格式 CODEC 和加密 CODEC,一般可以组合一起使用。在 ClickHouse 中,未显示指定 CODEC 的字段都会被分配一个 DEFAULT 默认 CODEC LZ4(除非用户修改 clickhouse 配置 compression 部分[17])。 压缩算法 CODEC 的选择是一个平衡板问题,更高的压缩度可以有更少的 IO 但是更高的 CPU,更低的压缩度有更多的 IO 但是更少的 CPU。这需要读者根据部署机器配置自行选择合适的压缩算法和压缩等级。 这里提供两个判断策略: 存储格式 CODEC 主要是 扩展阅读: 可以通过如下 SQL 查询当前所有表的 parts 信息: 可以通过如下查询获取当天 mrk 缓存命中情况: 以及如下查询获取当前 mrk 缓存内存占用情况: 以及 mrk 缓存具体缓存多少文件: 除此之外,ClickHouse 还可以调整 到了最难的部分,由于接下来的部分和不同业务息息相关,为了讲解我们业务上的优化,我先介绍下我们业务情况: QAPM 主打应用性能监控,主要分为指标、个例两张表。个例表包含更多基础字段,一般用户展示;指标表主要用于聚合计算。 首先确定主键,毋庸置疑的前两个一定是 指标没有特征键值,因此只添加处理时间作为第三个主键。 对于指标表,设置的主键为: 个例存在特征 feature,由于: 将特征的 md5 增加到主键中,用于加速查询、提高压缩率。但是这里有两个方向: 鉴于 数据插入看起来和查询性能没什么联系,但是有间接影响。不合理的插入会导致更多的写盘、更多的数据 merge 甚至有可能插入失败,影响读盘性能。 ClickHouse 作为 OLAP 并不适合小批量、大并发写入,相反而适合大批量、小并发写入,官方建议插入数据每批次至少 1000 行,或者每秒钟最多 1 次插入。[22] 这一小节我想强调原子(Atomic Insert)写入的概念:一次插入创建一个数据 part。 前文提及,ClickHouse 一个 part 是一个文件夹,后台有个 merge 线程池不断 merge 不同的 part。原子插入可以减少 merge 次数,让 ClickHouse 负载更低,性能更好。 原子写入的充分条件[23]: 这里贴一下我们生产的配置(users.xml)。 经过统计,个例表每行大约 2KB,指标表每行大约 100B(未压缩)。 设置 这三个配置项是客户端配置,需要在插入的 session 中设置,而不是在那几个 注意, ClickHouse 有 Shard 和 Replica 可以配置,作用如下图所示: 所谓读写分离也就是将 Shard 分为两半,一半只用于查询,只要让分布式表查询都导入到 Shard1 即可(在 这种策略有天然的缺陷: Buffer 并不推荐常规业务使用,只有在迫切需要查询实时性+插入无法大批量预聚合时使用: 该部分待补充,想看的同学可以在评论区踢踢 预聚合有三种方法,ETL、物化视图和投影,他们的区别如下[26]: 在我们业务中,个例是不应该预聚合的,因为数据需要被拉取展示而不用计算。指标需要聚合,数据量较大,每次实时计算对 ClickHouse 负载太大。 其实还有一种聚合方式,过期数据聚合。可以参考,同样限制要求 group by 的键值为主键前缀。 在我们业务使用时,什么时候用哪一个呢? 最后,为了避免集群被某个查询、插入弄垮,需要合理安排内存使用,需要给访问账户分权限,在我们业务分为: 同时建议设置 quota,减少大量读盘计算、LIMIT 少量数据返回的情况发生。 我们是 CSIG 性能工程二组 QAPM 团队,QAPM 时一款应用性能监控工具,覆盖 android、ios、小程序、mac 和 win 多端,已有腾讯会议、优衣库等大用户接入,值得信赖,欢迎同事试用我们 QAPM 产品~跳转链接 在 ClickHouse 优化过程遇到无数的问题,卡在 ClickHouse 自身监控无法覆盖的角落时,全靠性能工程三组员工的 Drop(雨滴)工具的鼎力相助,高效直观监控 CVM 各项指标,降低优化门槛,助力业务增效~跳转链接 脚注 [1]https://clickhouse.com/docs/en/faq/general/why-clickhouse-is-so-fast/ [2]https://benchmark.clickhouse.com [3]https://gcc.gnu.org/wiki/New_C_Parser [4]https://clang.llvm.org/features.html [5]https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree/#mergetree-data-storage [6]https://kb.altinity.com/engines/mergetree-table-engine-family/pick-keys/#partition-by [7]https://clickhouse.com/docs/en/guides/improving-query-performance/sparse-primary-indexes/sparse-primary-indexes-design/#data-is-organized-into-granules-for-parallel-data-processing [8]https://clickhouse.com/docs/en/guides/improving-query-performance/sparse-primary-indexes/sparse-primary-indexes-design/#the-primary-index-has-one-entry-per-granule [9]https://clickhouse.com/docs/en/guides/improving-query-performance/sparse-primary-indexes/sparse-primary-indexes-design/#the-primary-index-is-used-for-selecting-granules [10]https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree/#primary-keys-and-indexes-in-queries [11]https://clickhouse.com/docs/en/guides/improving-query-performance/sparse-primary-indexes/sparse-primary-indexes-design/#mark-files-are-used-for-locating-granules [12]https://kb.altinity.com/engines/mergetree-table-engine-family/pick-keys/#how-to-pick-an-order-by--primary-key [13]https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree/#settings [14]https://clickhouse.com/docs/en/sql-reference/data-types/nullable/#storage-features [15]https://groups.google.com/g/clickhouse/c/AP2FbQ-uoj8 [16]https://kb.altinity.com/altinity-kb-schema-design/best-schema-for-storing-many-metrics-registered-from-the-single-source/ [17]https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings/#server-settings-compression [18]http://www.vldb.org/pvldb/vol8/p1816-teller.pdf [19]https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings/#server-mark-cache-size [20]https://clickhouse.com/docs/en/operations/caches/ [21]https://kb.altinity.com/altinity-kb-queries-and-syntax/altinity-kb-sample-by/#sample-emulation-via-where-condition [22]https://clickhouse.com/docs/en/about-us/performance/#performance-when-inserting-data [23]https://github.com/ClickHouse/ClickHouse/issues/9195#issuecomment-587500824 [24]https://www.jianshu.com/p/c3a4cc528ce8 [25]https://github.com/ClickHouse/ClickHouse/issues/11783#issuecomment-647778852 [26]https://kb.altinity.com/altinity-kb-schema-design/preaggregations/ Linux内核可谓是集C语言大成者,从中我们可以学到非常多的技巧,本文来学习一下宏技巧,文章有点长,但耐心看完后C语言level直接飙升。 参考资料: Linux中常见如上定义宏的形式,我们都知道do{}while(0)只执行一次,那么这个有什么意义呢?我们写一个更简单的宏,来看看 则在这样的语句中: 被展开为 fun2(x)将不会执行!有同学会想,加个花括号 则在这样的语句中 被展开为 注意}后还有个;这将会出现语法错误。 但是假如我们写成 则完美避免上述问题! 写一个获取数组中元素个数的宏怎么写?显然用sizeof 可以用,但这样是存在问题的,先看个例子 输出: 为什么?因为数组名和指针不是完全一样的,函数参数中的数组名在函数内部会降为指针! sizeof(a),在函数中实际上变成了sizeof(int *)。上面的宏存在的问题也就清楚了,这是一个非常重大,且容易忽略的bug! 让我们看看,内核中怎么写: sizeof(arr) / sizeof((arr)[0]很好理解数组大小除去元素类型大小即是元素个数,真正的精髓在于后面__must_be_array(arr)宏 先看内部的__same_type,它也是个宏 __builtin_types_compatible_p 是gcc内联函数,在内核源码中找不到定义也无需包含头文件,在代码中也可以直接使用这个函数。(只要是用gcc编译器来编译即可使用,不用管这个,只需知道: 当 a 和 b 是同一种数据类型时,此函数返回 1。 当 a 和 b 是不同的数据类型时,此函数返回 0。 再看外部的(精髓来了) 上来就是个小技巧:!!(e)是将e转换为0或1,加个-号即将e转换为0或-1。 再用到了位域:有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。例如在存放一个开关量时,只有0和1 两种状态,用一位二进位即可。这时候可以用位域 a占用3位,b占用3位,如上结构体只占用2字节,位域可以为无位域名,这时它只用来作填充或调整位置,不能使用,如: 当位数为负数时编译无法通过!当a为数组时,__same_type((a), &(a)[0]),&(a)[0]是个指针,两者类型不同,返回0,即e为0,-!!(e)为0,sizeof(struct{ int:0; })为0,编译通过且不影响最终值。当a为指针时,__same_type((a), &(a)[0]),两者类型相同,返回1,即e为1,-!!(e)为-1,无法编译。 思考这个问题,你会怎么写 存在问题,例子如下: 输出: 明显不对,因为>运算符优先级大于&,所以会先进行比较再进行按位与。 存在问题,例子如下: 输出: 同样是优先级问题+优先级大于>。 避免了前两个出现的问题,但同样还有问题存在: 期望结果: 实际结果 尽管用括号避免了优先级问题,但这个例子中的j++实际上运行了两次。 下面进行详解。 3.4.1.GNU C中的语句表达式 表达式就是由一系列操作符和操作数构成的式子。 例如三面三个表达式 表达式加上一个分号就构成了语句,例如,下面三条语句: A compound statement enclosed in parentheses may appear as an expression in GNU C. ——《Using the GNU Compiler Collection》6.1 Statements and Declarations in ExpressionsGNU C允许在表达式中有复合语句,称为语句表达式: 语句表达式内部可以有局部变量,语句表达式的值为内部最后一个表达式的值。 例子: 输出:y=7。这个扩展使得宏构造更加安全可靠,我们可以写出这样的程序: 但这个宏还有个缺点,只能比较int型变量,改进一下: 但这需要传入type,还不够好。 3.4.2 typeof关键字 GNU C 扩展了一个关键字 typeof,用来获取一个变量或表达式的类型。 例子: 于是就有了 3.4.3真正的精髓 对比一下,内核的写法: 发现比我们的还多了一句 这才是真正的精髓,对于不同类型的指针比较,编译器会给一个警告: 提示两种数据类型不同。至于加void是因为当两个值比较,比较的结果没有用到,有些编译器可能会给出一个警告,加(void)后,就可以消除这个警告。 我们传给某个函数的参数是某个结构体的成员,但是在函数中要用到此结构体的其它成员变量,这时就需要使用这个宏:container_of(ptr, type, member)ptr为已知结构体成员的指针,type为结构体名字,member为已知成员名字,例子: 输出:s_a.b=8。本例子中通过struct_a结构体中的a成员地址获取到了结构体地址,进而对结构体中的另一成员b进行了赋值。 首先来看: 这个是获取在结构体TYPE中,MEMBER成员的偏移位置。 定义一个结构体变量时,编译器会按照结构体中各个成员的顺序,在内存中分配一片连续的空间来存储。例子: 输出 结构体的地址也就是第一个成员的地址,每一个成员的地址可以看作是对首地址的偏移,上面例子中,a就是首地址偏移0,b就是首地址偏移4字节,c就是首地址偏移8字节。 我们知道C语言中指针的内容其实就是地址,我们也可以把某个地址强制转换为某种类型的指针,(TYPE *)0)即将地址0,通过强制类型转换,转换为一个指向结构体类型为 TYPE的常量指针。 &((TYPE *)0)->MEMBER自然就是MEMBER成员对首地址的偏移量了。而(size_t)是内核定义的数据类型,在32位机上就是unsigned int,64位就是unsiged long int,就是强制转换为无符号整型数。再来看: 第一句(其实这句才是精华) typeof在前面讲过了,获取类型,这句作用是利用赋值来确保你传入的ptr指针和member成员是同一类型,不然就会出现警告。 第二句 有了前面的讲解,应该就很容易理解了,成员的地址减去偏移不就是首地址吗,为什么要加个(char *)强制类型转换? 因为offsetof(type, member)的结果是偏移的字节数,而指针运算,(char *)-1是减去一个字节,(int *)-1就是减去四个字节了。最外面的 (type *),即把这个值强制转换为结构体指针。 #运算符,可以把宏参数转换为字符串,例子 输出: ##运算符,可以把两个参数组合成一个。例子: 该程序的输出如下: 我们都知道printf接受可变参数,C99后宏定义也可以使用可变参数。C99 标准新增加的一个 __VA_ARGS__ 预定义标识符来表示变参列表,例子: 但是这个在使用时,可能还有点问题比如这种写法: 展开后 多了个逗号,编译无法通过,这时,只要在标识符__VA_ARGS__前面加上宏连接符##,当变参列表非空时,##的作用是连接fmt,和变参列表宏正常使用;当变参列表为空时,##会将固定参数fmt后面的逗号删除掉,这样宏也就可以正常使用了,即改成这样: 除了这些,其实Linux内核中还有很多宏和函数写得非常精妙。Linux内核越看越有味道,看内核源码,很多时候都会不明所以,但看明白后又醍醐灌顶,又感慨人外有人! 本文出自:大叔的嵌入式小站一个简单的嵌入式/单片机学习、交流小站
4月份的时候看到一道面试题,据说是腾讯校招面试官提的:在多线程和高并发环境下,如果有一个平均运行一百万次才出现一次的bug,你如何调试这个bug?知乎原贴地址如下: .
遗憾的是知乎很多答案在抨击这道题本身的正确性,虽然我不是这次的面试官,但我认为这是一道非常好的面试题。当然,只是道加分题,答不上,不扣分。答得不错,说明解决问题的思路和能力要超过应届生平均水平。
之所以写上面这段,是因为我觉得大部分后台服务端开发都有可能遇到这样的BUG,即使没有遇到,这样的题目也能够激发大家不断思考和总结。非常凑巧的是,我在4月份也遇到了一个类似的而且要更加严重的BUG,这是我自己挖的一个很深的坑,不填好,整个项目就无法上线。
现在已经过去了一个多月,趁着有时间,自己好好总结一下,希望里面提到的一些经验和工具能够带给大家一点帮助。
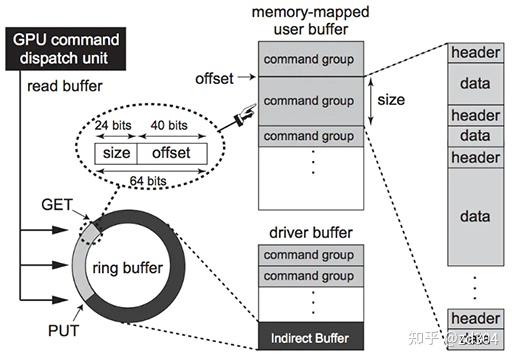
我们针对nginx事件框架和openssl协议栈进行了一些深度改造,以提升nginx的HTTPS完全握手计算性能。
由于原生nginx使用本地CPU做RSA计算,ECDHE_RSA算法的单核处理能力只有400 qps左右。前期测试时的并发性能很低,就算开了24核,性能也无法超过1万。
核心功能在去年底就完成了开发,线下测试也没有发现问题。经过优化后的性能提升几倍,为了测试最大性能,使用了很多客户端并发测试https性能。很快就遇到了一些问题: 其中第一和第二个问题的背景都是,只有并发上万qps以上时才有可能出现,几百或者一两千QPS时,程序没有任何问题。
首先说一下core的解决思路,主要是如下几点:
因为有core dump ,所以这个问题初看很容易定位。gdb 找到core dump点,btrace就能知道基本的原因和上下文了。
core的直接原因非常简单和常见,全部都是NULL指针引用导致的。不过从函数上下文想不通为什么会出现NULL值,因为这些指针在原生nginx的事件和模块中都是这么使用的,不应该在这些地方变成NULL。由于暂时找不到根本原因,还是先解决CORE dump吧,修复办法也非常简单,直接判断指针是否NULL,如果是NULL就直接返回,不引用不就完事了,这个地方以后肯定不会出CORE了。
在NULL处返回,确实避免了在这个地方的CORE,但是过几个小时又core 在了另外一个NULL指针引用上。于是我又继续加个判断并避免NULL指针的引用。悲剧的是,过了几个小时,又CORE在了其他地方,就这样过了几天,我一直在想为什么会出现一些指针为NULL的情况?为什么会CORE在不同地方?为什么我用浏览器和curl这样的命令工具访问却没有任何问题?
于是我更加迷惑,显然NULL值导致出CORE只是表象,真正的问题是,这些关键指针为什么会被赋值成NULL?
这个时候异步事件编程的缺点和复杂性就暴露了,好好的一个客户端的请求,从逻辑上应该是连续的,但是被读写及时间事件拆成了多个片断。虽然GDB能准确地记录core dump时的函数调用栈,但是却无法准确记录一条请求完整的事件处理栈。根本就不知道上次是哪个事件的哪些函数将这个指针赋值为NULL的,甚至都不知道这些数据结构上次被哪个事件使用了。
所以通过GDB无法准确定位 core 的真正原因 log debug的新尝试
这时候强大的GDB已经派不上用场了。怎么办?打印nginx调试日志。
但是打印日志也很郁闷,只要将nginx的日志级别调整到DEBUG,CORE就无法重现。为什么?因为DEBUG的日志信息量非常大,频繁地写磁盘严重影响了NGINX的性能,打开DEBUG后性能由几十万直线下降到几百qps。
调整到其他级别比如 INFO,性能虽然好了,但是日志信息量太少,没有帮助。尽管如此,日志却是个很好的工具,于是又尝试过以下办法:
总体思路依然是在不明显降低性能的前提下打印尽量详细的调试日志,遗憾的是,上述办法还是不能帮助问题定位,当然了,在不断的日志调试中,对代码和逻辑越来越熟悉。
这时候的调试效率已经很低了,几万QPS连续压力测试,几个小时才出一次CORE,然后修改代码,添加调试日志。几天过去了,毫无进展。所以必须要在线下构造出稳定的core dump环境,这样才能加快debug效率。
虽然还没有发现根本原因,但是发现了一个很可疑的地方: 出CORE比较集中,经常是在凌晨4,5点,早上7,8点的时候 dump几十个CORE。
联想到夜间有很多的网络硬件调整及故障,我猜测这些core dump可能跟网络质量相关。**特别是网络瞬时不稳定,很容易触发BUG导致大量的CORE DUMP。**
最开始我考虑过使用TC(traffic control)工具来构造弱网络环境,但是转念一想,弱网络环境导致的结果是什么?显然是网络请求的各种异常啊,所以还不如直接构造各种异常请求来复现问题。于是准备构造测试工具和环境,需要满足两个条件:
由于高并发流量时才可能出core,所以首先就需要找一个性能强大的压测工具。 是一款非常优秀的开源HTTP压力测试工具,采用多线程 + 异步事件驱动的框架,其中事件机制使用了redis的ae事件框架,协议解析使用了nginx的相关代码。
相比ab(apache bench)等传统压力测试工具的优点就是性能好,基本上单台机器发送几百万pqs,打满网卡都没有问题。
wrk的缺点就是只支持HTTP类协议,不支持其他协议类测试,比如protobuf,另外数据显示也不是很方便。
由于是HTTPS请求,使用ECDHE_RSA密钥交换算法时,客户端的计算消耗也比较大,单机也就10000多qps。也就是说如果server的性能有3W qps,那么一台客户端是无法发送这么大的压力的,所以需要构建一个多机的分布式测试系统,即通过中控机同时控制多台测试机客户端启动和停止测试。
之前也提到了,调试效率太低,整个测试过程需要能够自动化运行,比如晚上睡觉前,可以控制多台机器在不同的协议,不同的端口,不同的cipher suite运行整个晚上。白天因为一直在盯着,运行几分钟就需要查看结果。
这个系统有如下功能:
1. 并发控制多台测试客户端的启停,最后汇总输出总的测试结果。
2. 支持https,http协议测试,支持webserver及revers proxy性能测试。
3. 支持配置不同的测试时间、端口、URL。
4. 根据端口选择不同的SSL协议版本,不同的cipher suite。
5. 根据URL选择webserver、revers proxy模式。
压力测试工具和系统都准备好了,还是不能准确复现core dump的环境。接下来还要完成异常请求的构造。构造哪些异常请求呢?
由于新增的功能代码主要是和SSL握手相关,这个过程是紧接着TCP握手发生的,所以异常也主要发生在这个阶段。于是我考虑构造了如下三种异常情形:
构造好了上述高并发压力异常测试系统,果然,几秒钟之内必然出CORE。有了稳定的测试环境,那bug fix的效率自然就会快很多。
虽然此时通过gdb还是不方便定位根本原因,但是测试请求已经满足了触发CORE的条件,打开debug调试日志也能触发core dump。于是可以不断地修改代码,不断地GDB调试,不断地增加日志,一步步地追踪根源,一步步地接近真相。
最终通过不断地重复上述步骤找到了core dump的根本原因。其实在写总结文档的时候,core dump的根本原因是什么已经不太重要,最重要的还是解决问题的思路和过程,这才是值得分享和总结的。很多情况下,千辛万苦排查出来的,其实是一个非常明显甚至愚蠢的错误。
比如这次core dump的主要原因是:
由于没有正确地设置non-reusable,并发量太大时,用于异步代理计算的connection结构体被nginx回收并进行了初始化,从而导致不同的事件中出现NULL指针并出CORE。
虽然解决了core dump,但是另外一个问题又浮出了水面,就是**高并发测试时,会出现内存泄漏,大概一个小时500M的样子**。
出现内存泄漏或者内存问题,大家第一时间都会想到
valgrind是一款非常优秀的软件,不需要重新编译程序就能够直接测试。功能也非常强大,能够检测常见的内存错误包括内存初始化、越界访问、内存溢出、free错误等都能够检测出来。推荐大家使用。
valgrind 运行的基本原理是: 待测程序运行在valgrind提供的模拟CPU上,valgrind会纪录内存访问及计算值,最后进行比较和错误输出 我通过valgrind测试nginx也发现了一些内存方面的错误,简单分享下valgrind测试nginx的经验: 上面说了valgrind的功能和使用经验,但是valgrind也有一个非常大的缺点,就是它会显著降低程序的性能,官方文档说使用memcheck工具时,降低10-50倍
也就是说,如果nginx完全握手性能是20000 qps,那么使用valgrind测试,性能就只有400 qps左右。对于一般的内存问题,降低性能没啥影响,但是我这次的内存泄漏是在大压力测试时才可能遇到的,如果性能降低这么明显,内存泄漏的错误根本检测不出来。
只能再考虑其他办法了。
address sanitizer(简称asan)是一个用来检测c/c++程序的快速内存检测工具。相比valgrind的优点就是速度快, 介绍对程序性能的降低只有2倍。
对Asan原理有兴趣的同学可以参考 这篇文章,它的实现原理就是在程序代码中插入一些自定义代码,如下: 和valgrind明显不同的是,asan需要添加编译开关重新编译程序,好在不需要自己修改代码。而valgrind不需要编程程序就能直接运行。
address sanitizer集成在了clang编译器中,GCC 4.8版本以上才支持。我们线上程序默认都是使用gcc4.3编译,于是我测试时直接使用clang重新编译nginx: 由于AddressSanitizer对nginx的影响较小,所以大压力测试时也能达到上万的并发,内存泄漏的问题很容易就定位了。
这里就不详细介绍内存泄漏的原因了,因为跟openssl的错误处理逻辑有关,是我自己实现的,没有普遍的参考意义。 最重要的是,知道valgrind和asan的使用场景和方法,遇到内存方面的问题能够快速修复。
到此,经过改造的nginx程序没有core dump和内存泄漏方面的风险了。但这显然不是我们最关心的结果(因为代码本该如此),我们最关心的问题是:
1. 代码优化前,程序的瓶颈在哪里?能够优化到什么程度?
2. 代码优化后,优化是否彻底?会出现哪些新的性能热点和瓶颈?
这个时候我们就需要一些工具来检测程序的性能热点。
linux世界有许多非常好用的性能分析工具,我挑选几款最常用的简单介绍下:
1.[perf]( )应该是最全面最方便的一个性能检测工具。由linux内核携带并且同步更新,基本能满足日常使用。**推荐大家使用**。
2. ,我觉得是一个较过时的性能检测工具了,基本被perf取代,命令使用起来也不太方便。比如opcontrol --no-vmlinux , opcontrol --init等命令启动,然后是opcontrol --start, opcontrol --dump, opcontrol -h停止,opreport查看结果等,一大串命令和参数。有时候使用还容易忘记初始化,数据就是空的。
3. 主要是针对应用层程序的性能分析工具,缺点是需要重新编译程序,而且对程序性能有一些影响。不支持内核层面的一些统计,优点就是应用层的函数性能统计比较精细,接近我们对日常性能的理解,比如各个函数时间的运行时间,,函数的调用次数等,很人性易读。
4. 其实是一个运行时程序或者系统信息采集框架,主要用于动态追踪,当然也能用做性能分析,功能最强大,同时使用也相对复杂。不是一个简单的工具,可以说是一门动态追踪语言。如果程序出现非常麻烦的性能问题时,推荐使用 systemtap。
这里再多介绍一下perf命令,tlinux系统上默认都有安装,比如通过perf top就能列举出当前系统或者进程的热点事件,函数的排序。
perf record能够纪录和保存系统或者进程的性能事件,用于后面的分析,比如接下去要介绍的火焰图。
perf有一个缺点就是不直观。 就是为了解决这个问题。它能够以矢量图形化的方式显示事件热点及函数调用关系。
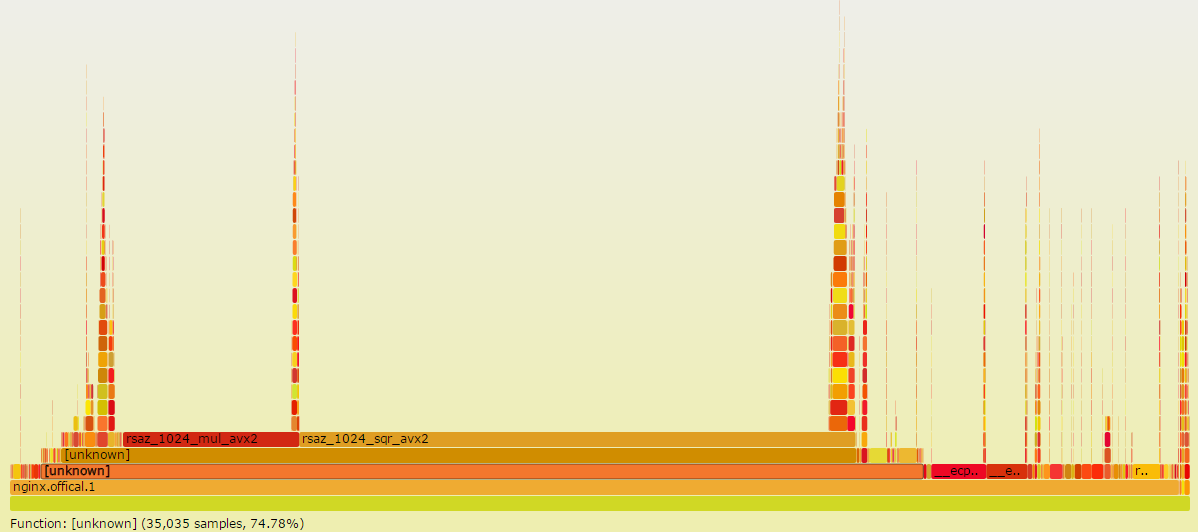
比如我通过如下几条命令就能绘制出原生nginx在ecdhe_rsa cipher suite下的性能热点: 直接通过火焰图就能看到各个函数占用的百分比,比如上图就能清楚地知道rsaz_1024_mul_avx2和rsaz_1024_sqr_avx2函数占用了75%的采样比例。那我们要优化的对象也就非常清楚了,能不能避免这两个函数的计算?或者使用非本地CPU方案实现它们的计算?
当然是可以的,我们的异步代理计算方案正是为了解决这个问题,
为了解决上面提到的core dump和内存泄漏问题,花了大概三周左右时间。压力很大,精神高度紧张, 说实话有些狼狈,看似几个很简单的问题,搞了这么长时间。心里当然不是很爽,会有些着急,特别是项目的关键上线期。但即使这样,整个过程我还是非常自信并且斗志昂扬。我一直在告诉自己: 2023年:100个Unity完整小游戏系列(教程+源码 ) 目前我在维护的免费技术群已经有6个,成员接近6000人,时间和精力实在是顾不过来了(但也不会解散)。如果大家后面想得到更专业的解答和技术指导,欢迎加入我的 知识星球:星星游戏开发,未来所有的小游戏源码和作业都会布置在知识星球核心群中,鼓励大家一起学习和成长。(PS:免费技术群还有少量的空位,入群方式可以往下翻,群满之后不再新增免费技术群,敬请谅解)。如果有工作上的困惑,欢迎和我一起探讨哈。 知识星球:星星游戏开发 公众号/小红书:放牛的星星 B站:叔叔的中年生活 第05期:小游戏 糖果传奇(三消) 第04期:俄罗斯方块 第03期:小游戏贪吃蛇(2种方式实现) 第02期:小游戏 数独 教学 文字教程: 视频教程: 第02期 前奏版:八皇后问题-递归与回溯算法 文字教程: 视频教程: 第01期:小游戏 2048 教学 (已完成 2023.7.25) 第00期:使用Unity制作一个时钟(Unity的下载与基础使用)(已完成 2023.7.21) 在知乎做Unity教程,从实战到各种教程翻译已经快200多篇文章了(有一部分已经准备好了,尚未发布)。我做教程的理念受 Jasper Flick 影响,我认为知识应该成体系的去讲解。 我的教程基本都是基于这个理念去做的。不管是原创系列还是翻译系列。但即使是成系统的去讲解了之后,在超过200篇的文章里仍然开始混乱不清,所以今天开一个新的主题,把已经小幅度汇总的系列再进行一次大的整理,就像Catlike一样。但内容不止局限于Jasper大神的系列。 喜欢的话,可以加qun: 460220051。群里有非常多的学习资料(若干个G): 还可以找管理员进微信群(或者 公众号:放牛的星星 获取微信进群/内推方式)。 有需求的可以找我进微信群(公众号:放牛的星星 获取微信进群方式),暂时没需求的也可以备用(不限工作年限和岗位,客户端、服务器、策划、美术、TA、运营都可以的哈),群里有各大厂的项目组和Leader直招,也有自身的猎头讲解行业信息。 0.1 干货盘点 0.2 面试经验 0.3 游戏优化 0.4 技术群活动 著名的CatLike教程。全部本人人肉翻译。这些教程会教有关Unity的C#和着色器编程的知识。 它介绍了新的编程概念,数学,算法和Unity功能。 它们对于新手和经验丰富的开发人员都非常有用。 所有已发教程的Demo源码可以访问下面的仓库下载。 基础教程,提供了在Unity中使用C#的介绍。(新手,熟悉C#语法和Unity编辑器) 基础教程,提供了在Unity中使用C#的介绍。相比于上面的旧版来说有非常大的改变,新手建议是两章都看一下,老鸟可以只看新的(增加了URP自定义渲染管线相关的内容)。 控制角色运动的系列教程。(新手,物理、碰撞) 一系列有关创建,跟踪,保存和加载对象的教程。(新手) 创建一个简单的基于网格的塔防游戏的系列。 一系列教程的内容,涵盖了水面等流动效果的创建。 程序网格的介绍。从简单的网格到可变形的球。 有关在Unity中创建自定义可编程渲染管线的教程的集合。使用Unity 2019及更高版本。 本系列将涵盖12篇文章,从最初自定义管线流程,到自定义管线的Shader格式,光线、阴影、全局光照等等方面全方位介绍可编程管线。 使用Unity 2018。 这是一个关于Unity默认渲染管线的教程系列。讲述了们如何将Mesh编程看起来像真实物体的像素。 这些教程涵盖了更复杂或专门的渲染技术,超越了Unity的标准着色器。它们以“基础渲染”系列中完成的工作为基础。 关于六边形图的系列。许多策略游戏都在使用它们。 其他老旧教程。由于教程过于久远,到时候视情况看看选一些进行翻译。 基于SLG类型的游戏,实际的技术选型和技术方案。 知乎更新不上来,放个链接看吧。 单独的一个小知识点。 一些自己写的,跟技术无关的文章。嘿嘿~ 先放这么多,持续更新中~~ 渲染技术总是伴随着显卡硬件的升级而发展的,从最初的GeForce 256开始支持T&L,到RTX支持光追,硬件和渲染技术都在不断更新。作为软件技术开发人员,平时更多是从软件视角去理解渲染。为了更进一步了解渲染的本质,本文换一个视角,收集并整理了一些资料,从GPU架构的角度来重新了解一下渲染。 GPU概括来讲,就是由显存和许多计算单元组成。 显存(Global Memory)主要指的是在GPU主板上的DRAM,类似于CPU的内存,特点是容量大但是速度慢,CPU和GPU都可以访问。 计算单元通常是指SM(Stream Multiprocessor,流多处理器),这些SM在不同的显卡上组织方式还不太一样。作为执行计算的单元,其内部还有自己的控制模块、寄存器、缓存、指令流水线等部件。 下面是Maxwell架构图和Turing架构图。 从Fermi开始NVIDIA使用类似的原理架构。 GPU包含若干个GPC(Graphics Processing Cluster,图形处理簇),不同架构的GPU包含的GPC数量不一样。例如Maxwell由4个GPC组成;Turing由6个GPC组成。 GPC包含若干个SM(Stream Multiprocessor,流多处理器),不同架构的GPU的GPC包含的SM数量不一样。例如Maxwell的一个GPC有4个SM;而Turing的一个GPC包含了6个TPC(Texture/Processor Cluster,纹理处理簇),每个TPC又包含了2个SM。 这里的SM就是本章节所说的计算单元,同时需要知道的是,程序员平时写的Shader就是在SM上进行处理的。 不同GPU厂商的架构中,SM的叫法不尽相同。 下图展示了一个SM的内部结构。 以Fermi架构的单个SM来说,其包含以下部件。 GPU类似于CPU也有自己的寄存器、L1 Cache、L2 Cache、显存,甚至必要时候还可以使用系统内存。 图中越往上,存取速度越快,越往下存取速度越慢。其中,Global Memory(全局内存)即我们通常所说的显存,通常放在GPU芯片的外部。L2 Cache是GPU芯片内部跨GPC而存在的。L1 Cache/Shared Memory、Uniform Cache、Tex Unit和Texture Cache以及寄存器都是存在于SM内部的。 它们的存取速度从寄存器到全局内存依次变慢: 如果从GPU硬件的视角下来看渲染管线,会看到一些不一样的东西,下图为GPU硬件视角下的渲染管线概要。 这个阶段主要是CPU在准备数据,包括图元数据、渲染状态等,并将数据传给GPU的过程。如下图所示就是数据如何进入GPU处理的过程。 CPU和GPU之间的数据传输是一个异步的过程,类似于服务器和客户端之间的数据传输。CPU和GPU构造了一种生产者/消费者异步处理模型。CPU生产“命令”,GPU消费“命令”,通过这种关系CPU就可以将数据和行为传输到GPU,GPU来执行对应动作。 CPU端通过调用渲染API(Graphics API),比如DX或者GL,将操作封装为一个一个的命令存放到命令队列中(FIFO Push Buffer),即上图中的PushBuffer。 当内存写满或者显示调用(Present或者Flush等)提交命令队列的时候,CPU将命令队列提交给应用驱动,并在命令队列末尾压入一条改变Fence值的命令。 接下来,通过系统驱动的调度,轮到这个应用传输的时候,就将数据写入到内存中的RingBuffer中。RingBuffer好比一个旋转的水车,将命令一点一点“搬运”到GPU的前端(Front End)。当这个“水车”满了,也就是RingBuffer满了,CPU就会发生拥塞。 当命令队列最后一条命令,也就是修改Fence值的命令被前端接收后,CPU接到了Fence修改的信号,拥塞就会被解除,CPU继续运行产生接下来的命令。 图元装配器(Primitive Distributor)根据图元类型、顶点索引以及图元装配命令,开始分配渲染工作,并发送给多个GPC处理。 PolyMorph Engine的Vertex Fetch模块通过三角形索引,将数据从显存中取得三角形数据,传入SM寄存器中。 前文说过Shader就是在SM上进行处理的。熟悉Shader开发的人都知道,Shader会对不同的“语义”进行处理,这些语义也叫“寄存器”。Shader中使用到的寄存器不光这些“语义”的寄存器,它们分为很多种类型,包括输入寄存器、常量寄存器、临时寄存器等。 数据进入SM后,线程调度器(Warp Scheduler)为每个Shader核心函数(VS/GS/PS等)创建一个线程,并在一个运算核心(Core)上执行该线程。根据Shader需要的寄存器数量,在寄存器堆(Register File)中为每个线程分配指定数量的寄存器。 同时,指令调度单元(Instruction Dispatch Unit)将Shader中的操作指令从指令缓存(Instruction Cache)中取出,并分配给每个运算核心去执行。 对于Shader的这种处理机制,不管是VS(Vertex Shader)还是PS(Pixel Shader),以及GS(Geometry Shader)等着色器来说都是相同的。换句话说,就是无论VS、PS、GS,都是在SM的运算核心里执行每一条指令的。 那么要深入理解SM工作的这种机制,这里需要解释一下三个重要的概念:统一着色器架构、SIMT和线程束。 Shader Model 在诞生之初就为我们提供了Pixel Shader(顶点着色器)和Vertex Shader(像素着色器)两种具体的硬件逻辑,它们是互相分置彼此不干涉的。 但是在长期的开发过程中,发现了以下的问题。 下图展示了Vertex Shader和Pixel Shader的负载对比。 在长期的发展过程中,NVIDIA和ATI的工程师都认为,要达到最佳的性能和电力使用效率,还是必须使用统一着色器架构才能解决上述问题。 在统一着色器架构的GPU中,Vertex Shader和Pixel Shader概念都将被废除,取而代之的就是“运算核心(Core)”。运算核心是个完整的图形处理体系,它既能够执行对顶点操作的指令(代替VS),又能够执行对象素操作的指令(代替PS)。GPU内部的运算核心甚至能够根据需要随意切换调用,从而极大的提升游戏的表现。 前文提到指令(Instruction)会经过调度单元(Dispatch Unit)的调度,分配到每一个运算核心去执行。 那么,指令是什么呢?其实指令可以理解为一条一条的操作命令,也就是告诉运算核心要怎么做的“描述语句”。比如 “将tmp25号寄存器里的值加上tmp26号寄存器里的值,得到的值存入tmp27号寄存器”这种操作,就是一条指令。 调度单元这里分配给每一个运行核心去执行的指令其实都是相同的。也就是说调度单元(Dispatch Unit)让每个运算核心在同一刻干的事情都是一样的。每一个运算核心虽然同一时刻做的操作是一样的,但是它们所操作的数据各自都是不同的。 举个例子,还是上面的这条指令——“将tmp25号寄存器里的值加上tmp26号寄存器里的值,得到的值存入tmp27号寄存器”。对于A运算核心和B运算核心来说,它们各自的tmp25号、tmp26号寄存器里存的值都是不一样的,以下为两个核心可能出现情况的例子。 这就是SIMT(Single Instruction Multiple Threads),T(线程,Threads)对应的就是运算核心(下文会介绍),翻译过来叫做“单指令多线程(运算核心)”,顾名思义,指令是相同的但是线程却不同。 通过上文的解释,我们还了解到了运算核心执行指令的另一个特征:运算核心执行指令的方式叫做“lock-step”。也就是所有运算核心同一时间执行的指令都是相同的,只有所有核心执行完当前指令,调度单元(Dispatch Unit)才会分配下一条指令给所有运算核心执行。 每个SM包含了很多寄存器,每个Shader核心函数(VS/GS/PS等)会当作一个线程去执行。Shader经过编译后,可以明确知道要执行的核心函数需要多少个寄存器,也就是说每个线程需要多少个寄存器是明确的。当线程要执行时,会从寄存器堆上分配得到这个线程需要数目的寄存器。比如一个SM总共有32768个寄存器,如果一个线程需要256个寄存器,那么这个SM上总共可以执行32768/256=128个线程。 SM上每一个运算核心同一时间内执行一个线程,也就是说一个线程其实是对应一个运算核心,但是,一个运算核心却是对应多个线程。这该怎么理解呢? 上文说到Shader所需要的寄存器数量决定了SM上总共能执行多少个线程。一个SM上总共也就有32个运算核心,但是如果多于32个线程需要执行怎么办? 线程调度器会将所有线程分为若干个组,每一个组叫做一个线程束(Warp),它又包含了32个线程。因此如果一个SM总共有32768个寄存器,这个SM总共可以执行128线程,那么这个SM上总共可以分配128/32=4个线程束。 一个运算核心同一时间只能处理一个线程,一组(32个)运算核心同一时间只能处理一个线程束,而线程束中有些指令处理起来会比较费时间,特别是内存加载。每当当前线程束(Warp)遇到费时操作,它就会被阻塞(Stall)。为了降低延迟,GPU的线程调度器会采用一种简单而有效的策略,就是切换另一组线程来运行。 运算核心在多个线程束(Warp)间切换着执行,最大化利用运算资源,也就解释了上文中所描述的线程和运算核心之间的关系了。 下图展示了一个SM执行三个线程束的例子。例子中一个线程束只有4个线程是一种简化图形的表示方式,根据上文可知,其实一个线程束中的线程数远大于4。下图中的txr指令延迟会比较高,所以容易使线程阻塞(Stall)。 细心的你如果仔细思考,也许会产生一个疑问:为什么线程调度器不去调度线程而是调度线程束? 通过上一小节介绍“SIMT”的时候我们了解到运算核心是以lock-step的方式执行的,也就是说线程执行的“步调”是一致的,每条指令对于所有线程来说都是“一起开始一起结束”。所以线程调度器调度的单位是线程束(Warp)。 由于线程束的机制,可以推出以下结论。由于寄存器堆的寄存器数量是固定的,如果一个Shader需要的寄存器数量越多,也就是每个线程分配到的寄存数量越多,那么线程束数量就越少。线程束少,供线程调度器调度的资源就少,当遇到耗时指令时,由于没有更多线程束去灵活调配,所有线程就只能死等,不利于资源的充分利用,最终导致执行效率低下。 当Warp完成了VS的所有指令运算,就会被PolyMorph Engine的Viewport Transform模块处理,并将三角形数据存放到L1和L2缓存里面。此时的三角形会被变换到裁剪空间(Clip空间),在这个空间下的顶点为像素处理阶段做好了准备。 为了平衡光栅化的负载压力,WDC(Work Distribution Crossbar)会根据一定策略,将屏幕划分成多个区域块,并重新分配给每一个GPC。下图为WDC为屏幕划分区域块的示意图。 前文提到GPC里有一个光栅化引擎(Raster Engine),这里GPC接收到分配的任务后,就是交给光栅化引擎来负责这些三角形像素信息的生成。同时还会处理其他的一些渲染流水线步骤,包括裁剪(Cliping)、背面剔除以及Early-Z。 接下来光栅化引擎将插值好的数据转交给PolyMorph Engine的Attribute Setup模块,将Vertex Shader计算后存放在L1和L2缓存里面的数据加载出来,经过插值的数据填充到Pixel Shader的寄存器里,供SM的运算核心做像素计算的时候使用。 在逻辑上,一个线程执行一个Pixel Shader的核心函数,也就是一个线程处理一个像素。GPU将屏幕分成一个一个的2×2的像素块,因为逻辑上一个Warp包含了32个线程,也就是说一个Warp处理的是8个像素块。 上文提到WDC会根据一定策略划分区域块,实际上的划分可能比上图更加复杂。网上有博主根据NV shader thread group提供的OpenGL扩展,基于OpenGL 4.3+和Geforce RTX 2060做了如下实验。 首先,应用程序画了两个覆盖全屏的三角形。顶点着色器就不赘述了,下面看看片元着色器。 渲染画面如下图所示。 图中有32个亮度色阶也就说明有32个不同编号的SM,由渲染结果可以看到SM的划分并不是按编号顺序简单地依次划分的。另外根据上图可见,同一个色块内的像素分属不同三角形,就会分给不同的SM进行处理。如果三角形越细碎,分配SM的次数就会越多。 这里一个色块是16×16,也就说明一个SM里运行了256个线程。 将片元着色器改为如下代码,显示Warp的分布情况。 渲染画面如下图所示。 由于一个色块是由4×8个像素组成,也就证明了一个Warp包含了32个线程。 经过PS计算,SM将数据转交给Crossbar,让它分配给ROP(渲染输出单元)。像素在这里进行深度测试以及帧缓冲混合等处理,并将最终值写入到一块FrameBuffer里面,这块FB就是双缓冲技术里面的后备缓冲。最终将FB写入到显存(DRAM)里。 关于IMR、TBR、TBDR介绍的文章有很多,下面简单归纳一下。 IMR架构主要是PC上GPU采用的渲染架构,这个架构主要是渲染快、带宽消耗大。 特点: IMR模式的GPU执行的伪代码如下。 问题: TBR全称Tile-Based Rendering,是一种基于分块的渲染架构。 分析: 为了解决以上IMR的问题,移动设备上的芯片采用了不一样的设计思路:不直接往显存的FrameBuffer里写入数据,而是将屏幕分成小块(Tile),每一个小块数据都存在On Chip Memory(类似L1和L2的缓存)上,合适的时候一次性渲染并将所有分块数据从On Chip Memory写入显存的FrameBuffer里。 由于不会频繁写入FrameBuffer,带宽消耗降低了,发热、耗电量问题都解决了;由于分块写入高速缓存On Chip Memory,芯片大小问题解决了。 特点: TB(D)R模式的GPU执行的伪代码如下。 TBDR全称Tile-Base-Deffered Rendering,是一种基于分块的延迟渲染架构。 分析: PowerVR设计了一个叫做ISP(Image Signal Processor)的处理单元,不依赖物体从远到近绘制,而是对图形做像素级的排序,完美通过像素级Early-Z降低Overdraw,这种技术称为HSR(Hidden Surface Removal)。 类似的技术比如:Adreno的Early Z Rejection,Mali的FPK(Forward Pixel Killing)。 前文提到过,如果寄存器使用过多,会导致Warp数量变少,使得GPU遇到耗时操作的时候没有空闲Warp去调度,不利于GPU的充分利用,因此要节约使用寄存器。 对于Shader的语义也好,寄存器也好,都是作为矢量存在的。对于GPU的ALU来说,一条指令可以处理的数据一般是四维(4D)的,这就是SIMD(Single Instruction Multiple Data),类似的SIMD指令可以参考SSE指令集。 例如下面的代码。 如果没有SIMD处理单元,汇编伪代码如下,四个数据需要四个指令周期才能完成。 而使用SIMD处理后就变为一条指令处理四个数据了,大大提高了处理效率。 由于SIMD的特性,寄存器要尽可能完全利用。例如Unity里有一个宏用来缩放并且偏移图片采样用的UV坐标——TRANSFORM_TEX。按道理缩放UV需要乘以一个二维向量,偏移UV也需要加一个二维向量,这里应该是需要两个寄存器的。然而Unity将两个二维向量都装入同一个四维向量里面(xy为缩放,zw为偏移),这样就只用到一个寄存器了。总而言之,要充分利用寄存器向量的每一个分量。其定义如下。 为了充分利用SIMD运算单元,GPU还提供了一种叫做co-issue的技术来优化代码。例如下图,由于float数量的不同,ALU利用率从100%依次下降为75%、50%、25%。 为了解决着色器在低维向量的利用率低的问题,可以通过合并1D与3D或2D与2D的指令。例如下图,原本的两条指令,co-issue会自动将它们合并,这样一个指令周期就可以执行完成。 但是如果其中一个变量既是操作数,又是存储数,则无法启用co-issue来优化。 于是标量指令着色器(Scalar Instruction Shader)应运而生,它可以有效地组合任何向量,开启co-issue技术,充分发挥SIMD的优势。 GPU和CPU由于其设计目标就有很大的区别,于是出现了非常不同的架构。 CPU有大量的存储单元(红色部分)和控制单元(黄色部分),相比起GPU来说,CPU的计算单元(绿色部分)只占了很少一部分。因此CPU不擅长大规模并行计算,更擅长于逻辑控制。相反,GPU擅长大规模并行计算,不擅长逻辑控制。 因此,不要在Shader里写逻辑控制语句,包括if-else和for循环等逻辑。下面介绍一下两种芯片在分支控制上都有哪些区别。 有人在JVM上做过一个测试。如果有一个有序数组,和一个同样大的无序数组,分别取出一百万次其数组中大于128的数字之和,消耗的时间是否相同呢? 以上这段代码,按实验步骤来做。 两次实验数据数量、循环次数以及实验算出来的最终结果都是一样的,为何两次消耗时间相差竟有3倍之多?要了解这个问题,就需要了解CPU的分支预测了。 一条指令在CPU上执行,需要经过以下四个步骤: 比较笨一点的办法就是,每一条指令等上一条的这四步都走完再执行。显然这样效率不是很高,其实当一条指令开始执行第二步decode时,下一条指令就可以开始执行第一步fetch了。同理,当一条指令开始执行execute,下一条指令就可以执行decode了,再下一条指令就可以执行fetch了。 那么如果if指令已经执行到decode了,接下来该执行if语句块里面的指令,还是该执行else语句块里面的指令,CPU还不知道,因为只有if条件判断执行完成才能知道接下来该执行哪个语句块里的指令。 此时,CPU会先尝试将上一次判断的历史记录拿来这一次作为判断条件来先用着,这就是所谓的“分支预测”。如果预测对了,那么对于性能来说就是赚了;如果预测错误,那么就从fetch开始用正确的值重新来执行,也不亏性能。 GPU讲究的是大规模并行计算,没有那么强大的逻辑控制,所以GPU也不会去做分支预测。那么GPU是怎么去处理条件分支判断的呢? 由于GPU的执行是以lock-step的方式锁步执行的,也就是每一个运算核心一定要执行完当前指令的所有步骤才能执行下一条指令,也就是前文中所说的“比较笨一点的办法”,所以GPU是没有分支预测的。但是GPU有一个特殊的机制叫做遮掩(mask out)。 如上图所示,同时有8个线程在执行右边代码的指令。有的线程满足x大于0,那么左图中黄色部分就会被执行,但是同一指令周期内,其他的线程x小于或等于0,这些线程的指令就会被遮掩,也就是虽然也是要消耗时间,但是不会被执行,就处于了等待。同理,满足else条件的语句在接下来的指令执行周期内执行浅蓝色部分,不满足的在同一指令周期内就被遮掩,处于等待。 被遮掩的代码同样是要消耗相同的指令周期时间去等待未被遮掩的代码执行。因此,如果一个Shader里有太多的if-else语句,就会白白浪费很多时间周期。 同样的原理应用在for循环上,如果有的线程循环3遍,有的线程循环5遍,就需要等待循环最久的那个线程执行完成才能继续往下执行,造成很多线程的浪费。 因此,在Shader中不是不能写逻辑控制语句,而是要思考一下有没有被浪费的资源。换句话说,Shader里不要用不固定的数值来控制逻辑执行。 通常一些需要从缓存里,甚至内存里读取数据的操作会比较费时,例如贴图采样的指令。 从上文中可以了解到,一般GPU架构里SFU这种处理单元比较少,因此特殊数学函数尽量少调用,例如pow、sin、cos等。 由于TB(D)R架构下数据会一直积攒到FrameData里,直到“合适”的时机才会清空。如果一直不调用clear指令就会一直将数据积累到FrameData里清不掉。如果不用RenderTexture了就及时Discard掉。 例如有一张RenderTexture,渲染之前调用clear就能清空前一次的FrameData,不用这张RenderTexture了,就及时调用Discard(),以提高性能。 频繁切换RenderTexture会导致频繁将Tile数据拷贝到FrameBuffer上,增加性能消耗。 Early-Z可以很好的降低Overdraw,但是某些操作会使Early-Z失效。 因此要做到以下几点。 FrameData里会储存当前帧变换过的图元列表,也就是顶点数据,FrameData数据会随着Drawcall数增加而增加,FrameData增大有可能会存储到其他地方,影响读写速度,因此在移动平台渲染上百万个顶点或者三四百Drawcall就比较吃力了。 本文主要归纳了GPU内部的一些基本单元及其作用,简单总结了一下对渲染架构的描述,并针对以上两方面介绍了一些优化性能的技巧。本文更多是归纳总结性质的,如果要更加深入的了解可以细读以下参考文章,如果有总结不到位的欢迎探讨。 《Life of a triangle - NVIDIA's logical pipeline》(翻译) 《剖析虚幻渲染体系(12)- 移动端专题Part 2(GPU架构和机制)》 《图形 3.4+3.5 正向渲染/延迟渲染 和 深度测试Early-z / Z-prepass(Z-buffer)》 Milvus 是全球最快的向量数据库,在最新发布的Milvus 2.2 benchmark中,Milvus相比之前的版本,取得了50%以上的性能提升。值得一提的是,在Master branch的最新分支中,Milvus的性能又更进一步,在1M向量串行执行的场景下取得了3ms以下的延迟,整体QPS甚至超过了ElasticSearch的10倍。 基于以上因素,有以下经验结论可以遵循: 对于大数据量,内存不足的场景,Milvus提供两种解决方案: DiskANN的关键参数: search_list: search_list越大,recall越高而性能越差。search_list的大小不应该小于K。 而对于较小的K,推荐把search_list和K的比值设置得相对大一些, 这个比值随着K增大可以逐渐靠近1。 2. IVF_PQ IVF参数 PQ参数 3) 构建索引和内存资源是否充足 HNSW参数 资源优先,选择IVF_FLAT或者IVF_SQ8索引 IVF类索引的参数跟IVFPQ类似,这里就不做过多的介绍了。 在选择好写入方式的基础上,还有几个经验需要关注: 经验4 - 谨慎使用标量过滤,删除特性等特性 当然,Milvus后续的版本会对以上能力做针对性的优化,尤其是删除和标量过滤的场景。Milvus新一代的标量执行引擎也已经在开发中,欢迎大家参与给出更多有建设性的意见。 compute shader的出现,是硬件GPU发展的结果。最开始的GPU中,顶点着色单元和片元着色单元完全独立,且一般片元着色单元会多一些。这导致的问题就是,开发者需要按照硬件分配的算力,分配VS和FS的复杂度。从而保证整体硬件负载均衡。 随着硬件发展,每个计算单元都可以进行VS和FS运算,因为都依赖于相同的计算单元。这个被发展起来的方向被叫做GPGPU(General Purpose Computing On GPUs)GPU通用计算。这种方法不需要通过图形流水线的单元,也能直接利用GPU的硬件单元进行并行计算。实现这种计算的Shader,就是Compute Shader。 传统的图形流水线,就是每次绘制Draw()指令需要通过的全部步骤 很明显可以发现,计算管线相比于图像管线节省了很多硬件开销。如Input Assembler, Tessellation, Rasterizer等。且创建Compute Pipeline需要的信息也少于Graphics Pipeline GPU被设计的方式,就是并行处理大量数据。在图形Shader中,往往一个Shader就对应大量的顶点或像素。为了实现这一设计目标,GPU主要依赖于两种硬件基础 上图展示GCN架构下Compute Unit信息 了解完Compute Unit后,将细节加入图形管线流程图 一个最简单的CS例子: numthread(8,8,1)代表每个Thread Group线程组是8*8*1的二维表格形式,如果是numthread(8,2,4)表示4张横向长度为8,竖向长度为2的表格,如下图5 在C#端执行CS,使用的是Dispatch()函数 dispatch最后三个参数,表示要使用多少个Thread Group,(4,3,2)表示4*3*2=24个线程组。类似2张横向长度为4,竖向长度为3的表格。表格中的每一格都是一个numthread(8,2,4)的thread group。 实际上,numthread 和 Dispatch 的三维 Grid 的设置方式只是方便逻辑上的划分,硬件执行的时候还会把所有线程当成一维的。因此 numthread(8, 8, 1) 和 numthread(64, 1, 1) 只是对我们来说索引线程的方式不一样而已,除外没区别。 接下来是硬件和线程的对应关系 在设置numthreads(8,2,4)线程组包含的线程个数时,应该设置为WaveFront的整数倍。这样当一个SIMD有两个或以上Wave排队被执行,当前执行的Wave因为Memory Stall等待时,SIMD会切换到下一个WaveFront执行。从而降低Latency。但这需要足够的Vector register。 当两个Thread Group之间交换数据时,会通过L2缓存。速度比较慢,应尽量避免 当Thread Group内部两个线程交换数据时,会通过Local Data Share(LDS)。速度非常快,甚至快过L1缓存 要在代码中使用LDS的话,需要在组内共享的变量前加上 groupshared标记 LDS 也会被其他着色阶段(shader stage)使用,例如像素着色器就需要 LDS 来插值。 有些变量在不同线程有不同的数值,变量在线程中独立。我们称之为"non-uniform",比如下图中的变量a。 有些变量在不同线程完全相同,变量在线程中是共享的。我们称之为"uniform",比如下图中的c,因为groupIndex是相同的。 non-uniform变量存储在Vector Registers(VGPR)中。每个non-uniform变量需要64 * size_of_variable的空间。 uniform变量存储在Scalar Registers(SGPR)中。每个uniform变量需要1 * size_of_variable的空间。 代码中应该尽量使用uniform变量,不仅运行速度更快,而且占用的内存量也更少。最重要的是如果Vector Registers被占用过,会导致分配给SIMD的WaveFront降低。 如果线程组只分配了4个线程 -[numthreads(4,1,1)],一个WaveFront依然会打包64个线程。SIMD一次执行16个线程,所以会为了这个WaveFront执行4次。其中绝大部分都是空算,浪费了大量并行计算的资源。 即使WaveFront中一个thread进入分支,整个WaveFront也需要执行。 使用Compute Shader实现Mipmap生成,可以做到比图形管线更快的速度。 加入我们需要将一张4096 * 4096的RT,压缩到1 * 1。中间状态都保存到mipmap 不同Level。 在图形管线FS中,只能操作render target中对应的像素,导致没办法访问pass中的完整输出。而且也没办法生成多个mip level,在一次Pass中。PS对GPU占用的利用率如下图。 可以看到,在每次level计算中间,都会有一次gap。这是因为: 而且在最后几个level的计算中,GPU的利用率非常低。 首先为了避免Compute Unit之间的交流,我们让每个线程组独立操作input texture上的一小块位置sub-square。 分配的线程组个数和线程组大小信息:dispatch(64,64,1), numthreads(8,8,1)。 线程和像素的对应关系(除了最后一次)如下图所示: 上一行表示: 因为1^2的过程是用另外一个compute shader处理。 下面一行: 计算过程: 使用compute Shader的性能效果: 最后生成mipmap的部分,视频中也没介绍具体代码(而且口音好重,有点听不懂)。写的不够详细,后面有时间专门出一篇文章~ 参考 https://www.youtube.com/watch?v=0DLOJPSxJEg Lele Feng:[Compute]Introduction to Compute Shader Lele Feng:[Compute]More Compute Shaders http://diaryofagraphicsprogrammer.blogspot.com/2014/03/compute-shader-optimizations-for-amd.html 码字到现在,刚好2023年1月1日零点。在22年的尾巴,自己和身边的人都发生了很多事情。总之希望大家新年快乐,新年健康! 本文分享自华为云社区《GaussDB(DWS)性能调优:indexscan导致的性能问题识别与优化 #【玩转PB级数仓GaussDB(DWS)】》,作者: 譡里个檔 。 通常跑批加工场景下,都是大数量做关联操作,通常不建议使用索引。有些时候因为计划误判导致使用索引的可能会导致严重的性能问题。本文从一个典型的索引导致性能的场景重发,剖析此类问题的特征,定位方法和解决方法。 1)在某局点POC测试时发现某SQL语句比较慢,原始SQL如下 2)查询此query的topSQL信息的warning字段,发现SQL自诊断信息中有索引相关告警信息。 3)查询此query的topSQL信息(如下图),分析历史执行信息,发现id=20的CStore Index Scan算子的耗时为90796.980ms,SQL执行总时长137135.658ms。CStore Index Scan算子的耗时占比为 66% 4)找到原始SQL语句,对查询语句中出现的表dwimd.dwi_md_contract 进行hint,强制其走顺序扫描,避免走indexscan(全量语句见附件) 5)对语句进行explain verbose,查看计划,发现计划符合预期(即表dwimd.dwi_md_contract走tablescan,对于列存表计划上显式为CStore Scan) 6)对语句执行EXPLAIN ANALYZE操作(即实际执行语句),查看实际执行时间如下,发现SQL语句性能提升近10倍。全量的执行信息见附件 现在来总结一下 C++ 中class/struct的优化。对于class,我们一般谈论的是设计,更多的考虑点是放在API和业务或者架构,很少从性能角度看这个问题。本文就从性能角度谈谈这个问题。 这里b的偏移量是400。通过指针或成员访问 b 的任何代码需要将偏移量编码为 32 位数字。如果a和b交换,那么两者都可以使用编码为 8 位有符号数的偏移量进行访问,这使得代码更紧凑,增大代码缓存,效率更高。 我们下面验证一下。 compiler gcc 11.2 并且c++11 且开启-O2选项的情况下。性能测试结果如下图1-1。 compiler clang 11.2 并且c++11 且开启-O2选项的情况下,性能测试结果如下图1-2。 可以证明我们之前所说的基本正确。 建议:将大数组和其他大对象排在结构或类的最后。最常用的数据成员排在第一位。 三个函数 Sum1、Sum2 和 Sum3 做着完全相同的事情,它们是同样有效。如果您查看编译器生成的代码,您会注意到一些编译器将为这三个函数编写完全相同的代码。x86-64 gcc 11.0 如下: Sum1 有一个隐含的'this' 指针,它与 Sum2 和 Sum3 中的 p 和 r 做同样的事情。 compiler gcc 11.2 并且c++11,开启-O2选项,性能测试结果如下图2-1。 可以通过以下方式使成员函数更快,如果它们不需要任何非静态访问,则将它们设为静态。静态成员函数不能访问任何非静态数据成员或非静态成员函数。静态成员函数比非静态成员函数更快,因为它不需要“this”指针。 插一句题外话,实际开发中,静态成员函数用到比较多的场景,一是单例。二是为了兼容C中的回调函数(如posix thread)。此外对于存在歧义的构造函数(参数类型和个数,顺序均相同),也可以用静态构造函数来消除歧义。 建议:成员函数中不需要用到this时用静态成员函数。 虚函数用于实现多态。准确的来说,是实现多态方法中的一种。多态类的每个实例有一个指向虚表的指针。这个所谓的虚表在运行时用于查找正确版本的虚函数。多态是面向对象程序可能比非面向对象的程序效率低的主要原因之一。 调用虚成员函数所花费的时间比调用非虚成员函数所花费的时间多几个时钟周期。如果虚函数版本发生变化,那么您可能会得到错误的预测。虚函数的预测与误预测规则 与 switch 语句相同。调用已知类型的对象的虚函数时,通常情况下编译器可以绕过调度机制(不需要在虚表中查询),我们需要知道这一点。 如上如果没有优化,编译器需要在一个虚表中查找是否调用p->f() 转到 C0::f 或 C1::f。但是优化编译器会看到 p 总是指向到类 C1 的对象,因此它可以直接调用 C1::f 而无需使用虚拟表。只有在编译时无法知道哪个版本时才需要运行时多态性。 建议:优先选择其他方式(CRTP)实现多态,如果可以的话。 该点建议和Effective C++ Item35 不谋而合。 运行时类型识别会向所有类对象添加额外信息,效率不高。 编译器选项:-fno-rtti 表示禁止生成每个具有虚函数的类的信息,以供 C++ 运行时类型识别功能(“dynamic_cast”和“typeid”)使用。选项开启后,编译成果物大小会变小相比不开启状态。 建议:优先关闭该选项,如果不需要用到typeid和相关异常诊断的话。 由于以下原因,派生类会有额外不必要的性能开销: ? 父类数据成员的大小加上子类成员的偏移量,访问总偏移量大于127bytes 的数据成员,不够紧凑。 ? parent 和 child 的成员函数可能存储在不同的模块中。这可能会导致大量跳跃和低效的代码缓存。 应对策略: 建议: 1.优先选择组合而不是继承。 2.确保调用的函数在每个函数附近来解决问题,其他的也存储在彼此附近。 构造函数如果它涉及内存或其他资源的分配。有多种方法可以避免这种浪费的内存块复制,例如: ? 使用对象的引用或指针 ? 使用“移动构造函数” ? 创建一个转移所有权的成员函数或友元函数或运算符 此外对于无效参数或者内存失败,构造函数会抛异常或者构造函数必须要做耗时的动作时。建议使用二阶段构造。从性能角度考虑,二阶段构造相比一阶段构造,几乎没有性能损失。(而且相比一阶段构造更安全) 建议:二阶段构造安全性更高,几乎没有性能损失,特定场景优先选择使用。 联合体是数据成员共享相同内存空间的结构。 7.1 优点 这个特性,传统的教材中介绍很多次,也是很多人对于联合体的固有直觉,在这不做介绍。 可以理解为对于同一个数据,不同的解释。实际开发过程中,涉及到协议,用联合体则代码会很优雅。 如下: 输出: 上面是传统做法。它有一个缺点-访问和给成员赋值比对内置类型的操作相对要花费更多的时间。这个问题可以通过实现一个由 这个想法是为了更快地初始化/分配数据成员的值。也就是说,我们用位运算构造一个整数,当它们存储在结构体中时,完全匹配位的布局,然后将其分配给一个 输出: 7.2 缺点 建议:不同时使用的数据成员,也不会出现overlap,且需要节省内存,优先选择联合体。 位域可能有助于使数据更紧凑。访问位域的成员是比访问结构的成员效率低。访问大型数组,如果它可以节省缓存空间或使文件更小,那么额外的时间可能是合理的。使用 << 和 | 组合写位域字段会比单独写更快。 例子: 不考虑溢出: 考虑溢出: 重载函数的不同版本被简单地视为不同的函数。使用重载函数没有性能损失。 重载运算符相当于一个函数。使用重载运算符与使用做同样事情的函数一样高效。 我们需要注意的是,具有多个重载运算符的表达式有可能将创建中间结果的临时对象。 例子: 可以通过以下方式避免为中间结果 (b+c) 创建临时对象 修改: 大多数编译器会在简单的情况下自动进行这种优化 模板类似于宏,因为模板参数被替换为它们在编译前的值。下面的例子说明了一个函数参数和模板参数: 在简单函数中,m 在运行时从调用者传递给被调用者。但在模板函数中,m 在编译时被替换为它的值,因此编译器看到常量 8 而不是变量 m。使用模板的好处是参数传递中的参数开销避免了。缺点是编译器需要创建一个新的实例。如果再考虑到许多不同的因素作为模板参数的调用场景,编译处理后的代码可以变得很大,会占用更多的缓存。 使用模板也开可以实现多态,模板类可用于实现编译时多态性,这比使用虚成员函数获得的运行时多态性更有效率。 模板实现编译时多态: 这种实现多态的方法叫递归奇异模板CRTP。 应用场景:原型模式,enable_shared_from_this 使用命名空间在执行速度方面没有成本。inline int abs(int x)
{
int y=x >> 31;
return (x + y) ^ y;
}inline int max(int x, int y)
{
return y&((x-y)>>31)|x&~((x-y)>>31);
}
int average=(x & y) + ((x ^ y) >> 1)#define st(x) do{ x }while (__LINE__==-1)#define LLD "%lld"long long multiply(long long x,long long y,long long p)// x * y % p
{
long long ret=0;
for(; y; y >>=1)
{
if(y & 1)ret=(ret + x) % p;
x=(x + x) % p;
}
return ret;
}容器框架原生化
虚拟机调优(profile-based compile)
线程调度管控
首页快照snapshot
扫码混合对焦
GPU运算
……
timer = WFTaskFactory::create_timer_task(1000000, timer_callback);
http_task1 = WFTaskFactory::create_http_task(url1, http_callback);
http_task2 = WFTaskFactory::create_http_task(url2, http_callback);
go_task = WFTaskFactory::create_go_task("go", go_func);
graph = WFTaskFactory::create_graph_task(graph_callback);
WFGraphNode& a = graph->create_graph_node(timer);
WFGraphNode& b = graph->create_graph_node(http_task1);
WFGraphNode& c = graph->create_graph_node(http_task2);
WFGraphNode& d = graph->create_graph_node(go_task);
/* Build the graph */
a-->b;
a-->c;
b-->d;
c-->d;
+-------+
+---->| Http1 |-----+
| +-------+ |
+-------+ +-v--+
| Timer | | Go |
+-------+ +-^--+
| +-------+ |
+---->| Http2 |-----+
+-------+
{
/* Build the graph */
a-->b;
a-->c;
b-->d;
c-->d;
}
->运算符,我们同样支持<—。并且它们都可以连着写。所以,以下程序都是合法且等价的:{
a-->b-->d;
a-->c-->d;
}
{
d<--b<--a;
d<--c<--a;
}
{
d<--b<--a-->c-->d;
}static inline WFGraphNode& operator --(WFGraphNode& node, int)
{
return node;
}
static inline WFGraphNode& operator > (WFGraphNode& prec, WFGraphNode& succ)
{
prec.precede(succ);
return succ;
}
static inline WFGraphNode& operator < (WFGraphNode& succ, WFGraphNode& prec)
{
succ.succeed(prec);
return prec;
}
static inline WFGraphNode& operator --(WFGraphNode& node)
{
return node;
}



你想要的 ClickHouse 优化,都在这里。
本节基于 ClickHouse 22.3 版本分析
clickhouser-server启动后会在 while 循环中等待请求,接收到查询后会调用executeQueryImpl()行数构建 AST、优化并生成执行计划 pipeline,最后在executeImpl()中多线程执行 DAG 获取结果,这篇文章只关心 SQL 执行,省略掉网络交互部分,查询执行流程如下图所示: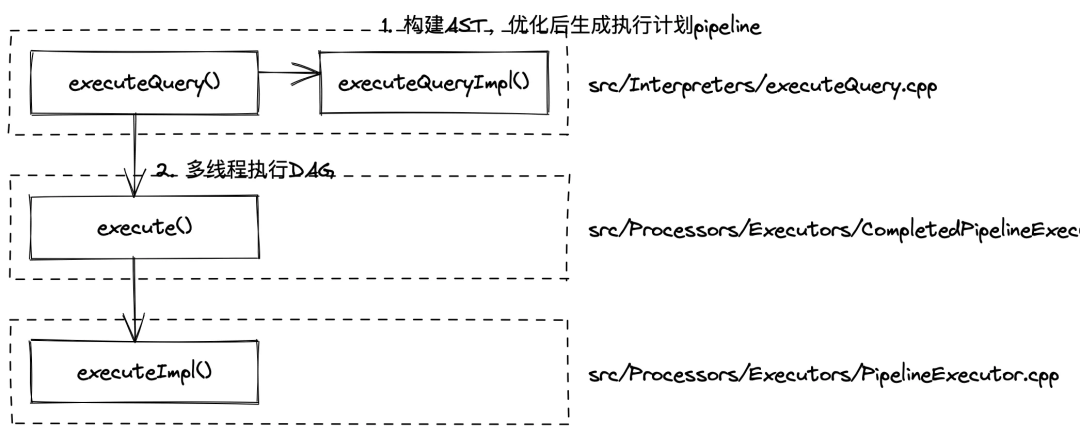
// src/Interpreters/executeQuery.cpp
static std::tuple<ASTPtr, BlockIO> executeQueryImpl()
{
// 构造Parser
ParserQuery parser(end, settings.allow_settings_after_format_in_insert);
// 将SQL转为抽象语法树
ast=parseQuery(parser, begin, end, "", max_query_size, settings.max_parser_depth);
// 设置query的上下文,比如SETTINGS
...
if (async_insert)
{
...
}else{
// 生成interpreter实例
interpreter=InterpreterFactory::get(ast, context, SelectQueryOptions(stage).setInternal(internal));
// interpreter优化AST并返回执行计划
res=interpreter->execute();
}
// 返回抽象语法树和执行计划
return std::make_tuple(ast, std::move(res));
}
// src/Parsers/parseQuery.cpp
ASTPtr tryParseQuery()
{
// 将SQL拆分为token流
Tokens tokens(query_begin, all_queries_end, max_query_size);
IParser::Pos token_iterator(tokens, max_parser_depth);
// 将token流解析为语法树
ASTPtr res;
const bool parse_res=parser.parse(token_iterator, res, expected);
return res;
}
perser.parse()函数进行语法分析,它的实现如下:// src/Parsers/ParserQuery.cpp
bool ParserQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected)
{
ParserQueryWithOutput query_with_output_p(end, allow_settings_after_format_in_insert);
ParserInsertQuery insert_p(end, allow_settings_after_format_in_insert);
ParserUseQuery use_p;
ParserSetQuery set_p;
ParserSystemQuery system_p;
ParserCreateUserQuery create_user_p;
ParserCreateRoleQuery create_role_p;
ParserCreateQuotaQuery create_quota_p;
ParserCreateRowPolicyQuery create_row_policy_p;
ParserCreateSettingsProfileQuery create_settings_profile_p;
ParserCreateFunctionQuery create_function_p;
ParserDropFunctionQuery drop_function_p;
ParserDropAccessEntityQuery drop_access_entity_p;
ParserGrantQuery grant_p;
ParserSetRoleQuery set_role_p;
ParserExternalDDLQuery external_ddl_p;
ParserTransactionControl transaction_control_p;
ParserBackupQuery backup_p;
bool res=query_with_output_p.parse(pos, node, expected)
|| insert_p.parse(pos, node, expected)
|| use_p.parse(pos, node, expected)
|| set_role_p.parse(pos, node, expected)
|| set_p.parse(pos, node, expected)
|| system_p.parse(pos, node, expected)
|| create_user_p.parse(pos, node, expected)
|| create_role_p.parse(pos, node, expected)
|| create_quota_p.parse(pos, node, expected)
|| create_row_policy_p.parse(pos, node, expected)
|| create_settings_profile_p.parse(pos, node, expected)
|| create_function_p.parse(pos, node, expected)
|| drop_function_p.parse(pos, node, expected)
|| drop_access_entity_p.parse(pos, node, expected)
|| grant_p.parse(pos, node, expected)
|| external_ddl_p.parse(pos, node, expected)
|| transaction_control_p.parse(pos, node, expected)
|| backup_p.parse(pos, node, expected);
return res;
}
// src/Interpreters/InterpreterFactory.cpp
std::unique_ptr<IInterpreter> InterpreterFactory::get()
{
...
if (query->as<ASTSelectQuery>())
{
return std::make_unique<InterpreterSelectQuery>(query, context, options);
}
...
}
InterpreterSelectQuery类的构造函数中将 AST 优化、重写,代码详见src/Interpreters/InterpreterSelectQuery.cpp,这里只画流程图:
src/Interpreters/InterpreterSelectQuery.cpp文件InterpreterSelectQuery::executeImpl()方法将优化分析得到的中间数据辅助生成最终的执行计划,代码如下:// src/Interpreters/InterpreterSelectQuery.cpp
void InterpreterSelectQuery::executeImpl()
{
...
// 个人理解针对EXPLAIN PLAN,只构建执行计划不执行
if (options.only_analyze)
{
...
}
else
{
// 从磁盘读取所需列,注意这一行,后文跳转进去分析
executeFetchColumns(from_stage, query_plan);
}
if (options.to_stage > QueryProcessingStage::FetchColumns)
{
// 在分布式执行Query时只在远程节点执行
if (expressions.first_stage)
{
// 当storage不支持prewhere时添加FilterStep
if (!query_info.projection && expressions.filter_info)
{
...
}
if (expressions.before_array_join)
{
...
}
if (expressions.array_join)
{
...
}
if (expressions.before_join)
{
...
}
// 可选步骤:将join key转为一致的supertype
if (expressions.converting_join_columns)
{
...
}
// 添加Join
if (expressions.hasJoin())
{
...
}
// 添加where
if (!query_info.projection && expressions.hasWhere())
executeWhere(query_plan, expressions.before_where, expressions.remove_where_filter);
// 添加aggregation
if (expressions.need_aggregate)
{
executeAggregation(
query_plan, expressions.before_aggregation, aggregate_overflow_row, aggregate_final, query_info.input_order_info);
/// We need to reset input order info, so that executeOrder can't use it
query_info.input_order_info.reset();
if (query_info.projection)
query_info.projection->input_order_info.reset();
}
// 准备执行:
// 1. before windows函数
// 2. windows函数
// 3. after windows函数
// 4. 准备DISTINCT
if (expressions.need_aggregate)
{
// 存在聚合函数,在windows函数/ORDER BY之前不执行
}
else
{
// 不存在聚合函数
// 存在windows函数,应该在初始节点运行
// 并且,ORDER BY和DISTINCT依赖于windows函数,这里也不能运行
if (query_analyzer->hasWindow())
{
executeExpression(query_plan, expressions.before_window, "Before window functions");
}
else
{
// 没有windows函数,执行before ORDER BY、准备DISTINCT
assert(!expressions.before_window);
executeExpression(query_plan, expressions.before_order_by, "Before ORDER BY");
executeDistinct(query_plan, true, expressions.selected_columns, true);
}
}
// 如果查询没有GROUP、HAVING,有ORDER或LIMIT,会在远程排序、LIMIT
preliminary_sort();
}
// 在分布式执行Query时只在初始节点执行或optimize_distributed_group_by_sharding_key开启时
if (expressions.second_stage || from_aggregation_stage)
{
if (from_aggregation_stage)
{
// 远程节点聚合过,这里啥也不干
}
else if (expressions.need_aggregate)
{
// 从不同节点拉取数据合并
if (!expressions.first_stage)
executeMergeAggregated(query_plan, aggregate_overflow_row, aggregate_final);
if (!aggregate_final)
{
// 执行group by with totals/rollup/cube
...
}
// 添加Having
else if (expressions.hasHaving())
executeHaving(query_plan, expressions.before_having, expressions.remove_having_filter);
}
// 报个错
else if (query.group_by_with_totals || query.group_by_with_rollup || query.group_by_with_cube)
throw Exception("WITH TOTALS, ROLLUP or CUBE are not supported without aggregation", ErrorCodes::NOT_IMPLEMENTED);
// 准备执行:
// 1. before windows函数
// 2. windows函数
// 3. after windows函数
// 4. 准备DISTINCT
if (from_aggregation_stage)
{
if (query_analyzer->hasWindow())
throw Exception(
"Window functions does not support processing from WithMergeableStateAfterAggregation",
ErrorCodes::NOT_IMPLEMENTED);
}
else if (expressions.need_aggregate)
{
executeExpression(query_plan, expressions.before_window,
"Before window functions");
executeWindow(query_plan);
executeExpression(query_plan, expressions.before_order_by, "Before ORDER BY");
executeDistinct(query_plan, true, expressions.selected_columns, true);
}
else
{
if (query_analyzer->hasWindow())
{
executeWindow(query_plan);
executeExpression(query_plan, expressions.before_order_by, "Before ORDER BY");
executeDistinct(query_plan, true, expressions.selected_columns, true);
}
else
{
// Neither aggregation nor windows, all expressions before
// ORDER BY executed on shards.
}
}
// 添加order by
if (expressions.has_order_by)
{
// 在分布式查询中,没有聚合函数却有order by,将会在远端节点order by
...
}
// 多source order by优化
...
// 多条流时再次执行distinct
if (!from_aggregation_stage && query.distinct)
executeDistinct(query_plan, false, expressions.selected_columns, false);
// 处理limit
...
// 处理projection
...
// 处理offset
...
}
// 需要子查询结果构建set
if (!subqueries_for_sets.empty())
executeSubqueriesInSetsAndJoins(query_plan, subqueries_for_sets);
}
}
InterpreterSelectQuery::executeFetchColumns()函数是读取所需列的阶段。从代码中可以看到它也做了很多的优化:count()优化quota限制count()、count(1)和count(*),ClickHouse 都有优化,但不要count(any_field)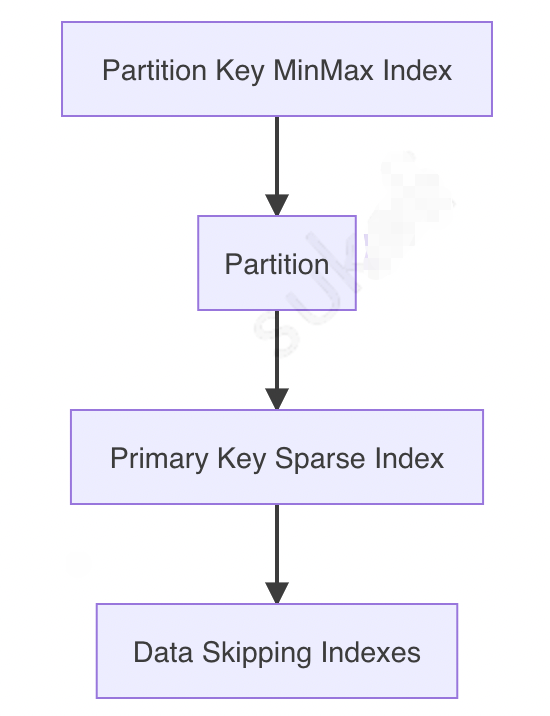
// src/Processors/QueryPlan/ReadFromMergeTree.cpp
MergeTreeDataSelectAnalysisResultPtr ReadFromMergeTree::selectRangesToRead()
{
...
try
{
// 使用partition by选取需要parts
MergeTreeDataSelectExecutor::filterPartsByPartition(...);
// 处理抽样
...
// 使用主键索引和跳表索引
result.parts_with_ranges=MergeTreeDataSelectExecutor::filterPartsByPrimaryKeyAndSkipIndexes(...);
}
catch(...)
{
...
}
...
}
.mrk和.bin文件,以及一个minmax_{PARTITION_KEY_COLUMN}.idx文件,不同 part 的 minmax 作为一个索引存储于内存。index_granularity设置的大小(默认 8192)将数据分为一个个 granules[7].bin文件存储了 n 个 granules,用.mrk文件记录每一个 granules 在.bin文件的地址偏移[11]force_index_by_date和force_primary_key避免全盘读取ttl_only_drop_parts表配置ttl_only_drop_parts=1。只有 parts 中所有数据都过期了才会 DROP,可以有效减少TTL_MERGE发生的频率,降低磁盘负载。merge_with_ttl_timeout=86400。配合上一项配置,将 TTL 检查调整为 1 天一次(默认 4 小时一次)。use_minimalistic_part_header_in_zookeeper=1。可以有效降低 Zookeeper 负载,避免 Zookeeeper 成为性能瓶颈(插入)。.bin和.mrk两个文件,而读取 Nullable 字段时需要.bin、.mrk和 masks 文件。社区查询验证,最高会有 2 倍性能损失。[15]metric1, metric2...metricN和tag1, tag2...tagN等等字段。metric_array、tag_array。Delta、DoubleDelta、Gorilla、FPC和T64几种。Delta存储行之间的变化值,适合变化较小且比较固定的列,比如时间戳。需要配合 ZSTD 使用DoubleDelta存储Delta的Delta。适合变化很慢的序列Gorilla适合不怎么变动的 integer、float 类型[18]FPC适合于 float 类型,由于我们未使用 float 字段这里略过T64存储编码范围内最大、最小值,以转为 64bit 存储,适合较小的 integer 类型mark_cache_size可以调整.mrk文件的缓存大小,默认为 5GB。适当调大可以减少查询时 IO 次数,有效降低磁盘压力。[19].mrk文件越大index_granularity与.mrk文件大小成负相关SELECT
database,
table,
count() AS parts,
uniqExact(partition_id) AS partition_cnt,
sum(rows),
formatReadableSize(sum(data_compressed_bytes) AS comp_bytes) AS comp,
formatReadableSize(sum(data_uncompressed_bytes) AS uncomp_bytes) AS uncomp,
uncomp_bytes / comp_bytes AS ratio,
formatReadableSize(sum(marks_bytes) AS mark_sum) AS marks,
mark_sum / uncomp_bytes AS mark_ratio
FROM cluster(default_cluster, system.parts)
WHERE active
GROUP BY
database,
table
ORDER BY comp_bytes DESC
WITH (ProfileEvents.Values[indexOf(ProfileEvents.Names, 'MarkCacheHits')]) AS MARK_CACHE_HITS
SELECT
toHour(event_time) AS time,
countIf(MARK_CACHE_HITS !=0) AS hit_query_count,
count() AS total_query_count,
hit_query_count / total_query_count AS hit_percent,
avg(MARK_CACHE_HITS) AS average_hit_files,
min(MARK_CACHE_HITS) AS minimal_hit_files,
max(MARK_CACHE_HITS) AS maximal_hit_files,
quantile(0.5)(MARK_CACHE_HITS) AS "50",
quantile(0.9)(MARK_CACHE_HITS) AS "90",
quantile(0.99)(MARK_CACHE_HITS) AS "99"
FROM clusterAllReplicas('default_cluster', system.query_log)
WHERE event_date=toDate(now())
AND (type=2 OR type=4)
AND query_kind='Select'
GROUP BY time
ORDER BY time ASC
SELECT formatReadableSize(value)
FROM asynchronous_metrics
WHERE metric='MarkCacheBytes'
SELECT value
FROM asynchronous_metrics
WHERE metric='MarkCacheFiles'
uncompressed_cache缓存一定量原始数据于内存中。[20]但是这个缓存只对大量短查询有效,对于 OLAP 来说,查询千奇百怪,不太建议调整这个配置。app_id, category, entrance_timeapp_id, category, intDiv(entrance_time, 3600000), feature_md5app_id, category, feature_md5, entrance_time分区键设置为`PARTITION BY intDiv(entrance_time, 2592000000)
SAMPLE BY需要将 xxHash 字段放在主键中,主键都包含高基数字段,就不设置抽样键,而是在需要的时候软抽样[21]:SELECT count() FROM table WHERE ... AND cityHash64(some_high_card_key) % 10=0; -- Deterministic
SELECT count() FROM table WHERE ... AND rand() % 10=0; -- Non-deterministic
MergeTree表(不能有 Buffer 表)max_insert_block_size(默认 1048545)input_format_parallel_parsing=0max_block_sizemin_insert_block_size_rows and min_insert_block_size_bytesMergeTree表不包含物化视图min_insert_block_size_rows为 10000000,指标会先满足这个条件,大概一个 block 原始大小 1GB。设置min_insert_block_size_bytes为 4096000000,个例会先满足这个条件,大概一个 block 原始大小 1G,约 1024000 行。.xml中配置。max_insert_block_size: 16777216
input_format_parallel_parsing: 0
min_insert_block_size_rows: 10000000
min_insert_block_size_bytes: 1024000000
min_insert_block_size_rows和min_insert_block_size_bytes是“或”的关系:// src/Interpreters/SquashingTransform.cpp
bool SquashingTransform::isEnoughSize(size_t rows, size_t bytes) const
{
return (!min_block_size_rows && !min_block_size_bytes)
|| (min_block_size_rows && rows >=min_block_size_rows)
|| (min_block_size_bytes && bytes >=min_block_size_bytes);
}
:本方案并没有经过生产验证,酌情考虑
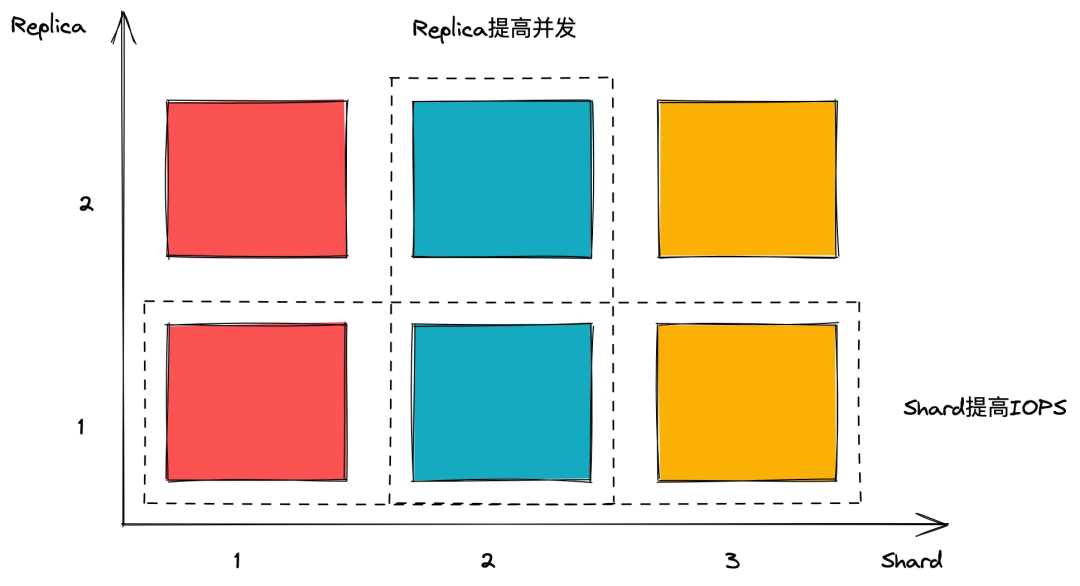
users.xml中配置load_balancing为first_or_random);一半用于写入,插入的程序手动控制插入 Shard2 的节点,由 ClickHouse 的 ReplicatedMergeTree 不同 Shard 数据依靠 zookeeper 自动同步的策略将数据同步到 Shard1。[24] :或许可以配置两边 Shard 资源不一致来解决问题,比如写入的 Shard 资源拉低,专用于处理数据插入;读的 Shard 资源更高,专门用于处理突增并发流量。
ETL MV Projections Realtime no yes yes How complex queries can be used to build the preaggregaton any complex very simple Impacts the insert speed no yes yes Are inconsistancies possible Depends on ETL. If it process the errors properly - no. yes (no transactions / atomicity) no Lifetime of aggregation any any Same as the raw data Requirements need external tools/scripting is a part of database schema is a part of table schema How complex to use in queries Depends on aggregation, usually simple, quering a separate table Depends on aggregation, sometimes quite complex, quering a separate table Very simple, quering the main table Can work correctly with ReplacingMergeTree as a source Yes No No Can work correctly with CollapsingMergeTree as a source Yes For simple aggregations For simple aggregations Can be chained Yes (Usually with DAGs / special scripts) Yes (but may be not straightforward, and often is a bad idea) No Resources needed to calculate the increment May be signigicant Usually tiny Usually tiny default:最高级账号,不使用root:数据插入,配置聚合写入部分的几个配置项monitor:内部开发使用,权限较高viewer:web 使用,添加大量限制viewer账户配置如下所示:<yandex>
<profiles>
<query>
<max_memory_usage>10000000000</max_memory_usage>
<max_memory_usage_for_all_queries>100000000000</max_memory_usage_for_all_queries>
<max_rows_to_read>1000000000</max_rows_to_read>
<max_bytes_to_read>100000000000</max_bytes_to_read>
<max_rows_to_group_by>1000000</max_rows_to_group_by>
<group_by_overflow_mode>any</group_by_overflow_mode>
<max_rows_to_sort>1000000</max_rows_to_sort>
<max_bytes_to_sort>1000000000</max_bytes_to_sort>
<max_result_rows>100000</max_result_rows>
<max_result_bytes>100000000</max_result_bytes>
<result_overflow_mode>break</result_overflow_mode>
<max_execution_time>60</max_execution_time>
<min_execution_speed>1000000</min_execution_speed>
<timeout_before_checking_execution_speed>15</timeout_before_checking_execution_speed>
<max_columns_to_read>25</max_columns_to_read>
<max_temporary_columns>100</max_temporary_columns>
<max_temporary_non_const_columns>50</max_temporary_non_const_columns>
<max_subquery_depth>2</max_subquery_depth>
<max_pipeline_depth>25</max_pipeline_depth>
<max_ast_depth>50</max_ast_depth>
<max_ast_elements>100</max_ast_elements>
<readonly>1</readonly>
</query>
</profiles>
</yandex>

#define init_hashtable_nodes(p, b) do{ \\
int _i; \\
hash_init((p)->htable##b); \\
...略去 \\
}while (0)#define fun(x) fun1(x);fun2(x);if(a)
fun(a);if(a)
fun1(x);fun2(x);;#define fun(x){fun1(x);fun2(x);}if (a)
fun(a);
else
fun3(a);if (a)
{fun1(x);fun2(x);};
else
fun3(a);#define fun(x) do{fun1(x);fun2(x);}while(0)#define ARRAY_SIZE(arr) (sizeof(arr) / sizeof(*arr))#include<stdio.h>
int a[3]={1,3,5};
int fun(int c[])
{
printf("fun1 a=%d\
",sizeof(c));
}
int main(void)
{
printf("a=%d\
",sizeof(a));
fun(a);
return 0;
}a=12;
b=8;//32位电脑为4#define ARRAY_SIZE(arr) (sizeof(arr) / sizeof((arr)[0]) + __must_be_array(arr))#define __must_be_array(a) BUILD_BUG_ON_ZERO(__same_type((a), &(a)[0]))# define __same_type(a, b) __builtin_types_compatible_p(typeof(a), typeof(b))#define BUILD_BUG_ON_ZERO(e) (sizeof(struct{ int:-!!(e); }))struct struct_a{
char a:3;
char b:3;
char c;
};struct struct_a{
char a:3;
char :3;
char c;
};#define MAX(a,b) a > b ? a : b#include<stdio.h>
#define MAX(x,y) x > y ? x: y
int main(void)
{
int i=14;
int j=3;
printf ("i&0b101=%d\
",i&0b101);
printf ("j&0b101=%d\
",j&0b101);
printf("max=%d\
",MAX(i&0b101,j&0b101));
return 0;
}i&0b101=4
j&0b101=1
max=1#define MAX(a,b) (a) > (b) ? (a) : (b)#define MAX(x,y) (x) > (y) ? (x) : (y)
int main(void)
{
printf("max=%d",3 + MAX(1,2));
return 0;
}max=1#define MAX(a,b) ((a) > (b) ? (a) : (b))#include<stdio.h>
#define MAX(x,y) ((x) > (y) ? (x): (y))
int main(void)
{
int i=2;
int j=3;
printf("max=%d\
",MAX(i++,j++));
printf("i=%d\
",i);
printf("j=%d\
",j);
return 0;
}max=3,i=3,j=4max=4,i=3,j=5#define MAX(x, y) ({ \\
typeof(x) _max1=(x); \\
typeof(y) _max2=(y); \\
(void) (&_max1==&_max2); \\
_max1 > _max2 ? _max1 : _max2; })a+b
i=a*2
a++a+b;
i=a*2;
a++;({表达式1;表达式2;表达式3;...})int main()
{
int y;
y=({ int a=3; int b=4;a+b;});
printf("y=%d\
",y);
return 0;
}int main()
{
int y;
y=({ int a=3; int b=4;a+b;});
printf("y=%d\
",y);
return 0;
}#define max(type,x, y) ({ \\
type _max1=(x); \\
type _max2=(y); \\
_max1 > _max2 ? _max1 : _max2; })int a;
typeof(a) b=1;
typeof(int *) a;
int f();
typeof(f()) i;#define max(x, y) ({ \\
typeof(x) _max1=(x); \\
typeof(y) _max2=(y); \\
_max1 > _max2 ? _max1 : _max2; })#define max(x, y) ({ \\
typeof(x) _max1=(x); \\
typeof(y) _max2=(y); \\
(void) (&_max1==&_max2); \\
_max1 > _max2 ? _max1 : _max2; })(void) (&_max1==&_max2);warning:comparison of distinct pointer types lacks a cast#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \\
const typeof(((type *)0)->member) *__mptr=(ptr); \\
(type *)((char *)__mptr - offsetof(type, member)); \\
})struct struct_a{
int a;
int b;
};
int fun1 (int *pa)
{
struct struct_a *ps_a;
ps_a=container_of(pa,struct struct_a,a);
ps_a->b=8;
}
int main(void)
{
float f=10;
struct struct_a s_a={2,3};
fun1(&s_a.a);
printf("s_a.b=%d\
",s_a.b);
return 0;
}#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)#include<stdio.h>
struct struct_a{
int a;
int b;
int c;
};
int main(void)
{
struct struct_a s_a={2,3,6};
printf("s_a addr=%p\
",&s_a);
printf("s_a.a addr=%p\
",&s_a.a);
printf("s_a.b addr=%p\
",&s_a.b);
printf("s_a.c addr=%p\
",&s_a.c);
return 0;
}s_a addr=0x7fff2357896c
s_a.a addr=0x7fff2357896c
s_a.b addr=0x7fff23578970
s_a.c addr=0x7fff23578974#define container_of(ptr, type, member) ({ \\
const typeof(((type *)0)->member) *__mptr=(ptr); \\
(type *)((char *)__mptr - offsetof(type, member)); \\
})const typeof(((type *)0)->member) *__mptr=(ptr); \\ (type *)((char *)__mptr - offsetof(type, member)); \\#include <stdio.h>
#define PSQR(x) printf("The square of " #x " is %d.\
",((x)*(x)))
int main(void)
{
int y=5;
PSQR(y);
PSQR(2 + 4);
return 0;
}The square of y is 25.
The square of 2 + 4 is 36.#include <stdio.h>
#define PRINT_XN(n) printf("x" #n "=%d\
", x ## n);
int main(void)
{
int x1=2;
int x2=3;
PRINT_XN(1); // becomes printf("x1=%d\
", x1);
PRINT_XN(2); // becomes printf("x2=%d\
", x2);
return 0;
}x1=2
x2=3#define DEBUG(...) printf(__VA_ARGS__)
int main(void)
{
DEBUG("Hello %s\
","World!");
return 0;
}#define DEBUG(fmt,...) printf(fmt,__VA_ARGS__)
int main(void)
{
DEBUG("Hello World!");
return 0;
}printf("Hello World!",);#define DEBUG(fmt,...) printf(fmt,##__VA_ARGS__) 这样的防守式编程并不提倡,指针NULL引用如果不core dump,而是直接返回,那么这个错误很有可能会影响用户的访问,同时这样的BUG还不知道什么时候能暴露。所以CORE DUMP 在NULL处,其实是非常负责任和有效的做法。
熟悉nginx代码的同学应该很清楚,nginx极少在函数入口及其他地方判断指针是否为NULL值。特别是一些关键数据结构,比如‘ngx_connection_t’及SSL_CTX等,在请求接收的时候就完成了初始化,所以不可能在后续正常处理过程中出现NULL的情况。
举个例子:客户端发送一个正常的get请求,由于网络或者客户端行为,需要发送两次才完成。服务端第一次read没有读取完全部数据,这次读事件中调用了 A,B函数,然后事件返回。第二次数据来临时,再次触发read事件,调用了A,C函数。并且core dump在了C函数中。这个时候,btrace的stack frame已经没有B函数调用的信息了。
traffic control是一个很好的构造弱网络环境的工具,我之前用过测试SPDY协议性能。能够控制网络速率、丢包率、延时等网络环境,作为iproute工具集中的一个工具,由linux系统自带。但比较麻烦的是TC的配置规则很复杂,facebook在tc的基础上封装成了一个开源工具apc,有兴趣的可以试试。
nginx的测试用法: wrk -t500 -c2000 -d30s https://127.0.0.1:8443/index.html
编译前:
*address=...; // or: ...=*address;
编译后:
if (IsPoisoned(address)){
ReportError(address, kAccessSize, kIsWrite);
}
*address=...; // or: ...=*address;` --with-cc="clang" \\
--with-cc-opt="-g -fPIC -fsanitize=address -fno-omit-frame-pointer"
其中with-cc是指定编译器,with-cc-opt指定编译选项, -fsanitize=address就是开启AddressSanitizer功能。
放牛的星星:100个Unity完整小游戏(3)-贪吃蛇
https://www.bilibili.com/video/BV11h4y1N7Pe
放牛的星星:100个Unity完整小游戏(4)-贪吃蛇(Unity 2D实现版)
放牛的星星:100个Unity完整小游戏(1)-2048
https://www.bilibili.com/video/BV1hc411w7qF
放牛的星星:100个Unity完整小游戏系列(0)用Unity做一个时钟
为了提高视频播放量 我决定教会老婆写代码_哔哩哔哩_bilibili






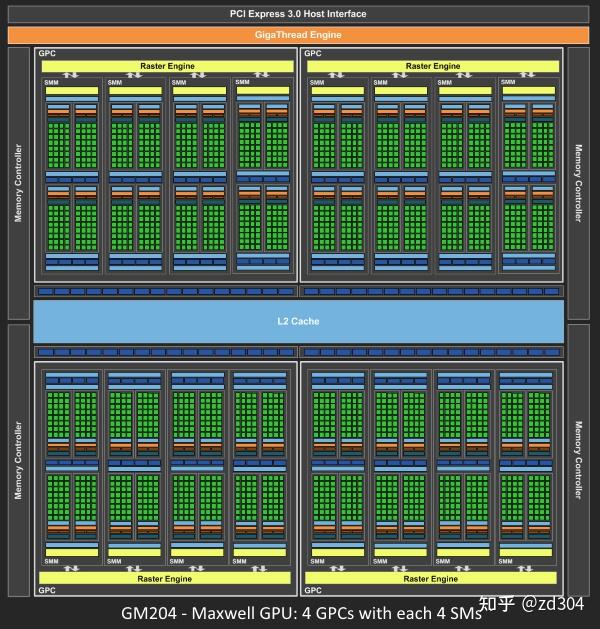
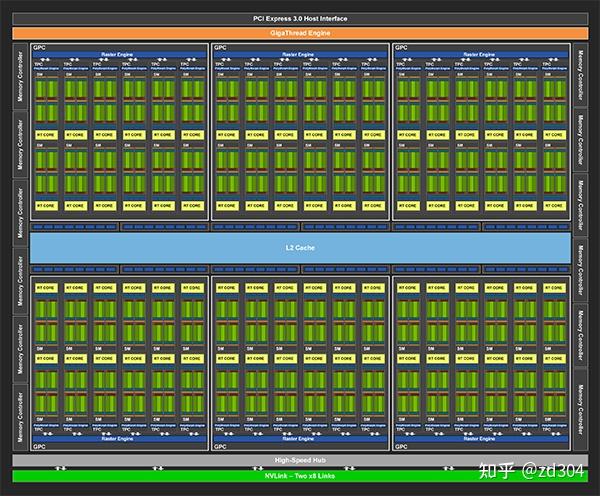
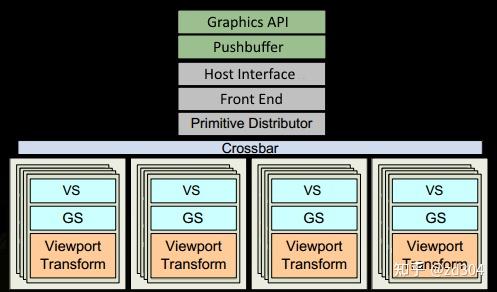
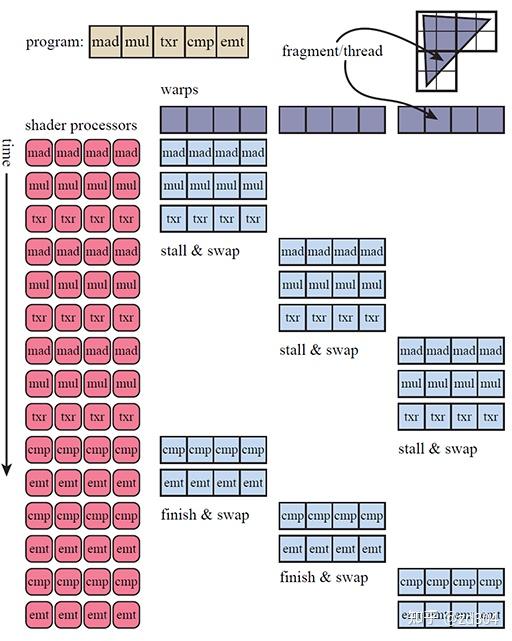
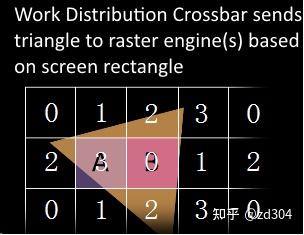
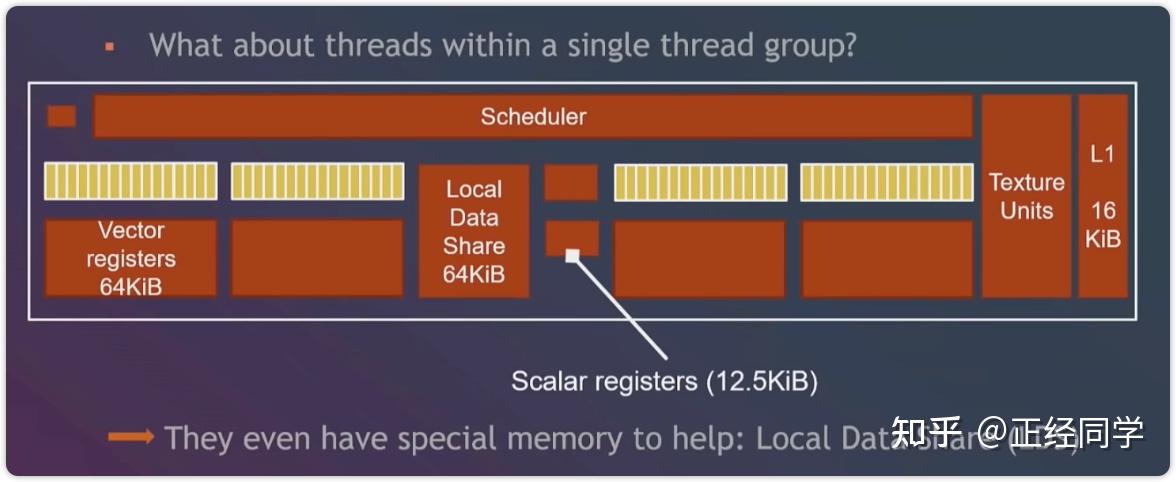
补充:GPC里除了有SM还有一些其它的部件,比如光栅化引擎(Raster Engine)。另外,连接每个GPC靠的是Crossbar,例如某一个GPC计算完的数据需要另外GPC来处理,这个分配就是靠的Crossbar。
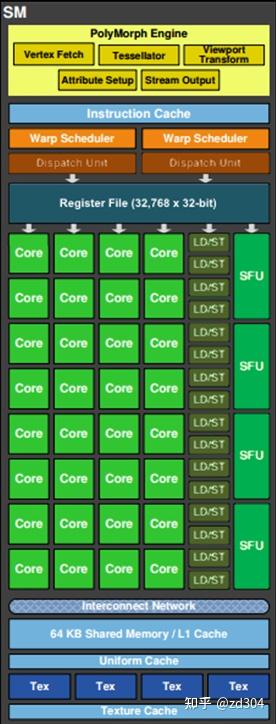
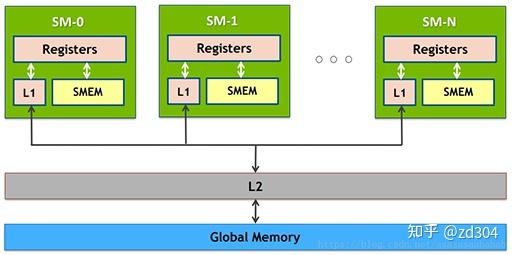
存储类型 访问周期 寄存器 1 共享内存 1~32 L1缓存 1~32 L2缓存 32~64 纹理、常量缓存 400~600 全局内存 400~600 
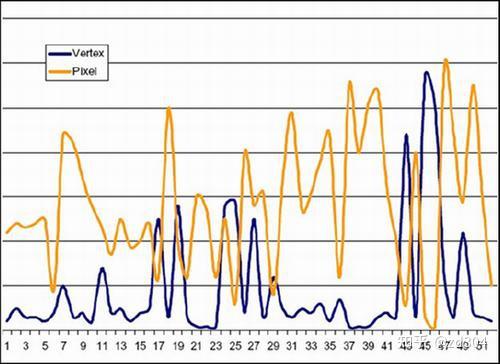
Shader Model 2.0/2.X Shader Model 3.0 Shader Model 4.0 临时寄存器 ≥12 32 4096 VS常量寄存器 ≥256 ≥256 14×4096 PS常量寄存器 32 224 14×4096 VS纹理 None 4 128×512 PS纹理 16 16 128×512 VS输入寄存器 16 16 16 插值寄存器 8 10 16/32 PS输出寄存器 4 4 8 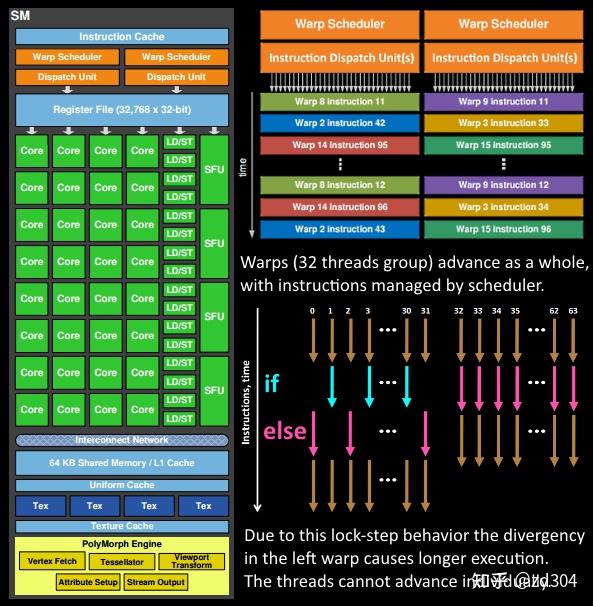
#version 430 core
#extension GL_NV_shader_thread_group : require
uniform uint gl_WarpSizeNV; // 单个线程束的线程数量
uniform uint gl_WarpsPerSMNV; // 单个SM的线程束数量
uniform uint gl_SMCountNV; // SM数量
in uint gl_WarpIDNV; // 当前线程束id
in uint gl_SMIDNV; // 当前线程所在的SM id,取值[0, gl_SMCountNV-1]
in uint gl_ThreadInWarpNV; // 当前线程id,取值[0, gl_WarpSizeNV-1]
out vec4 FragColor;
void main()
{
// SM id
float lightness = gl_SMIDNV / gl_SMCountNV;
FragColor = vec4(lightness);
}

// warp id
float lightness = gl_WarpIDNV / gl_WarpsPerSMNV;
FragColor = vec4(lightness);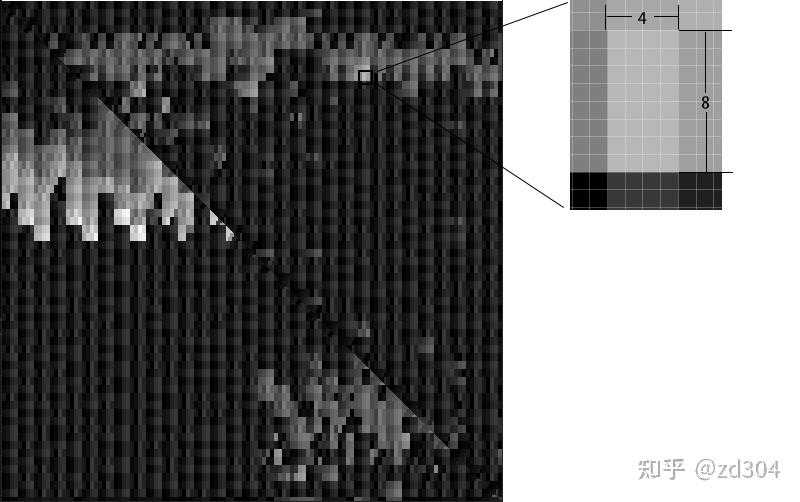

for (draw in renderPass)
{
for (primitive in draw)
{
execute_vertex_shader(vertex);
}
if (primitive is culled)
break;
for (fragment in primitive)
{
execute_fragment_shader(fragment);
}
}
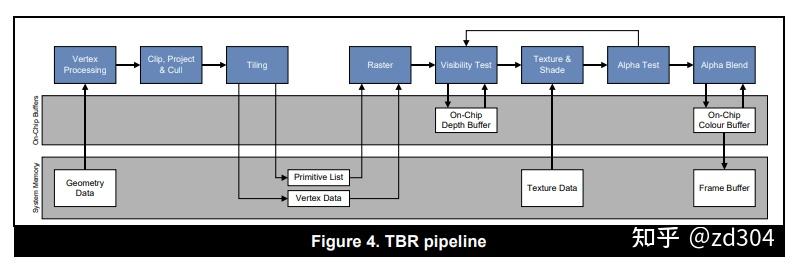
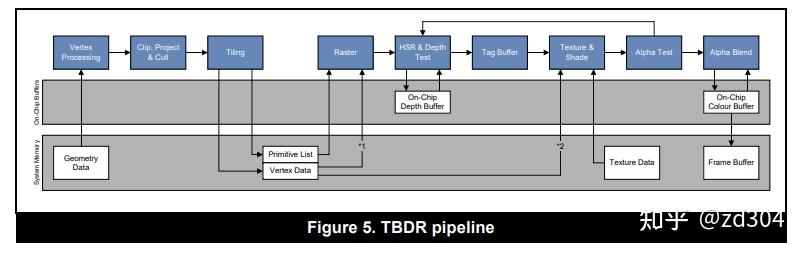
// Pass one
for (draw in renderPass)
{
for (primitive in draw)
{
for (vertex in primitive)
{
execute_vertex_shader(vertex);
}
if (primitive not culled)
{
append_tile_list(primitive);
}
}
}
// Pass two
for (tile in renderPass)
{
for (primitive in tile)
{
for (fragment in primitive)
{
execute_fragment_shader(fragment);
}
}
}
float4 c = a + b;ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.wSIMD_ADD c, a, b// Transforms 2D UV by scale/bias property
#define TRANSFORM_TEX(tex,name) (tex.xy * name##_ST.xy + name##_ST.zw)
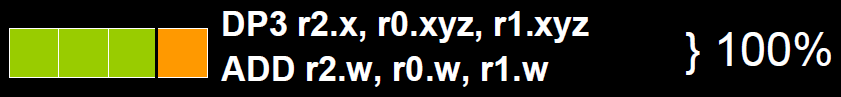

long long sum = 0;
for (unsigned i = 0; i < 1000000; ++i)
{
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}

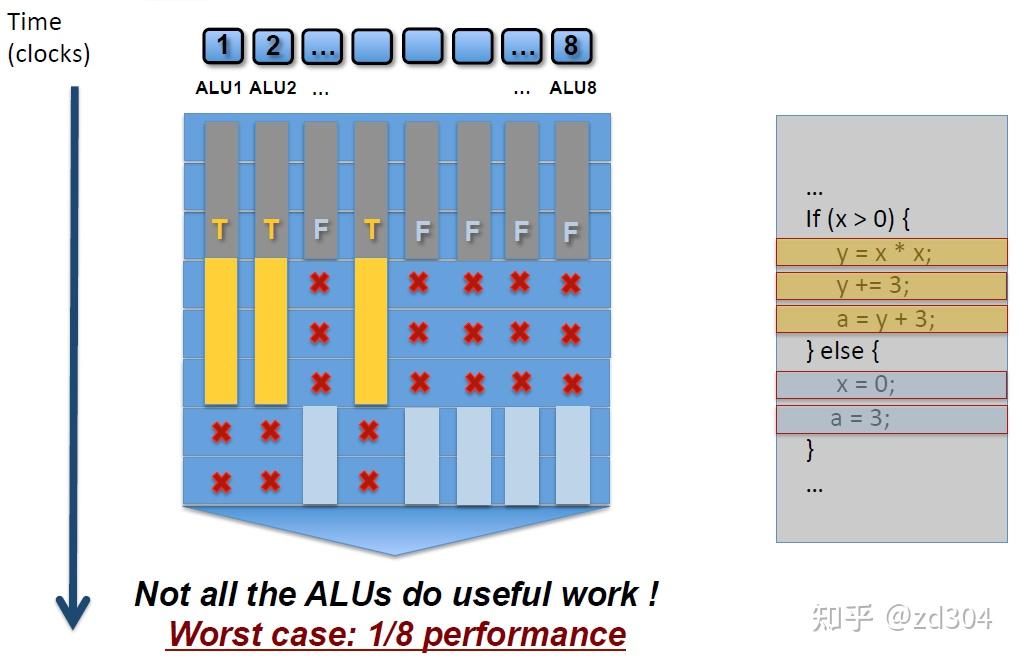
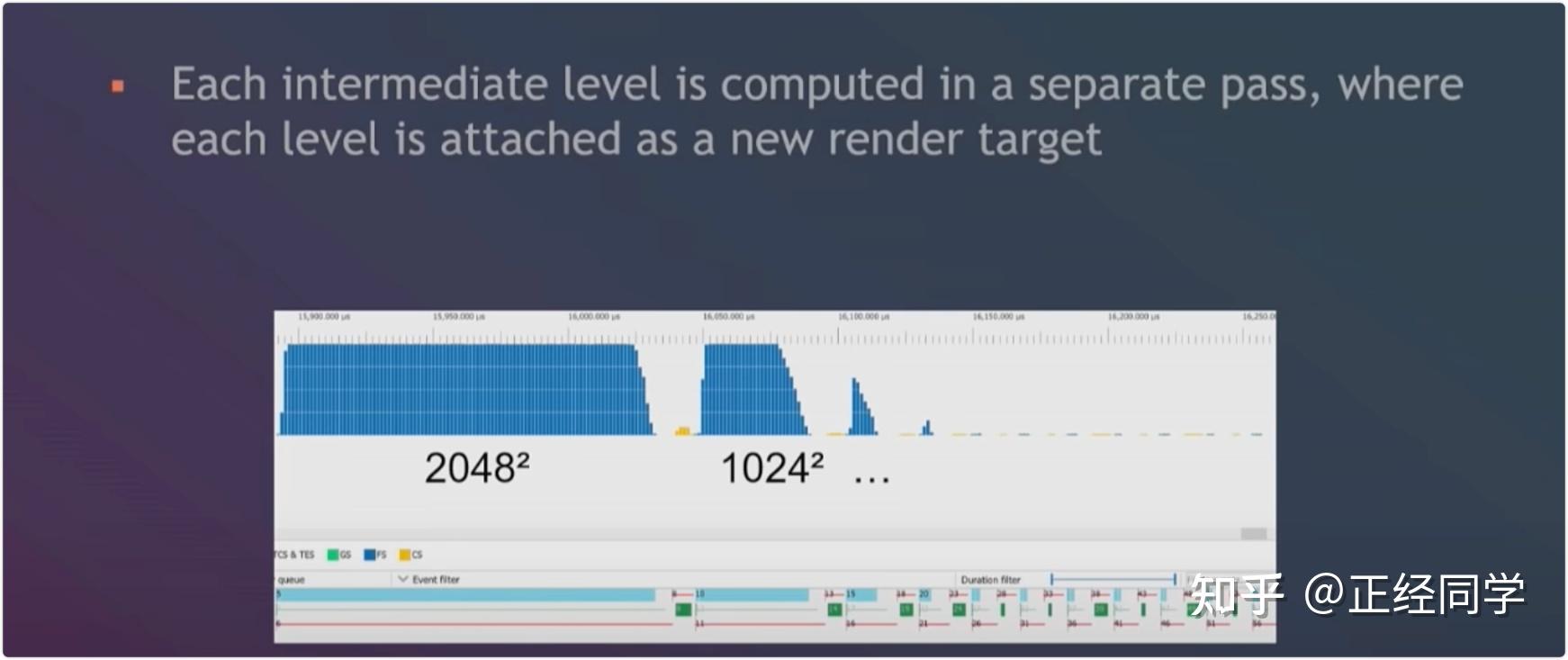
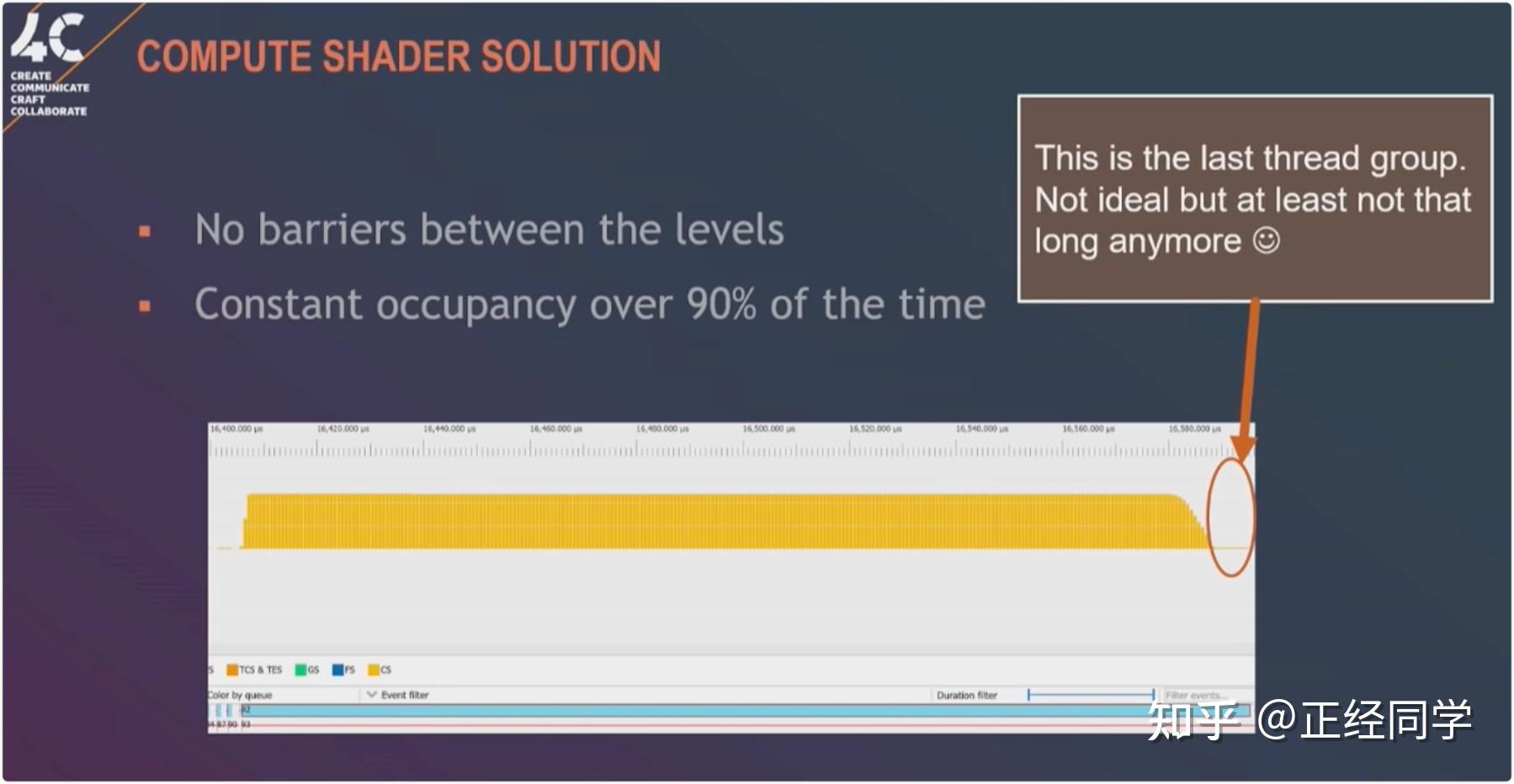
特别说明:因为Early-Z是通过深度去屏蔽不透明物体的,如果透明物体(Alpha Blend)或者挖洞的物体(Alpha Test)通过深度测试屏蔽了背景的不透明(Opaque)物体,那么背景就会镂空,看到clear指令指定的固有色,就会出现渲染错误,因此无论IMR还是T(D)BR的Early-Z都会受Alpha Test影响。
那么,如何使用Milvus才能达到理想的性能呢?本文暂且不提社区大神贡献的黑科技优化,先聊聊使用Milvus过程中一些经验,以及如何进行性能调优。
经验1 - 合理的预计数据量,表数目大小,QPS参数等指标
在部署Milvus之前,首先需要决定机器的资源,规格,以及一些依赖的资源,以下是你需要考虑的因素:
经验2 - 选择合适的索引类型和参数
索引的选择对于向量召回的性能至关重要,Milvus支持了Annoy,Faiss,HNSW,DiskANN等多种不同的索引,用户可以根据对延迟,内存使用和召回率的需求进行选择。
索引的选择步骤一般如下:
1) 是否需要精确结果?
只有Faiss的Flat索引支持精确结果,但需要注意Flat索引检索速度很慢,查询性能通常比其他Milvus支持的索引类型低两个数量级以上,因此只适合千万级数据量的小查询(Flat on GPU 已经在路上了,敬请期待)
2)数据量是否能加载进内存?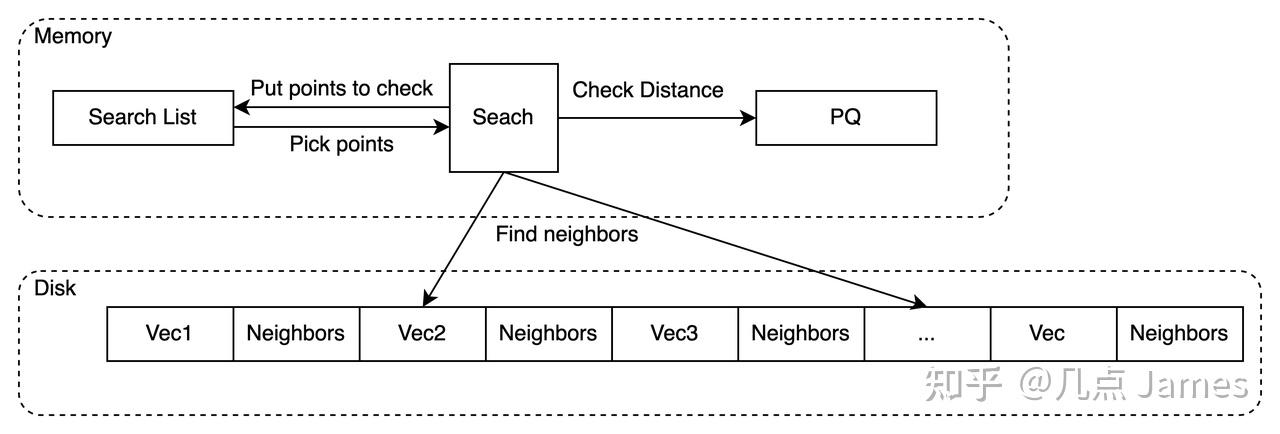
nlist:一般建议nlist=4*sqrt(N),对于Milvus而言,一个Segment默认是512M数据,对于128dim向量而言,一个segment包含100w数据,因此最佳nlist在1000左右。
nprobe:nprobe可以Search时调整搜索的数据量,nprobe越大,recall越高,但性能越差。具体的nprobe需要根据查询的精度要求决定,从nprobe=16开始会是一个不错的尝试。
M: 向量做PQ的分段数目,一般建议设置为向量维数的1/4,M取值越小内存占用越小,查询速度越快,精度也变得更加低。
Nbits: 每段量化器占用的bit数目,默认为8,不建议调整
性能优先,选择HNSW索引
M:表示在建表期间每个向量的边数目,M越大,内存消耗越高,在高维度的数据集下查询性能会越好。通常建议设置在8-32之间
ef_construction: 控制索引时间和索引准确度,ef_construction越大构建索引越长,但查询精度越高。要注意ef_construction 提高并不能无限增加索引的质量,常见的ef_construction参数为128.
ef: 控制搜索精确度和搜索性能,注意ef必须大于K。
检索时,Milvus的查询一致性也会对查询造成较大影响。通常情况,对于一致性要求较高的场景,建议使用最终一致性或者有界一致,默认情况下Milvus选择有界一致性,窗口为3s。
经验3 - 合理选择流式插入和批量导入
Mivus原生支持流批一体,同时支持流式写入和批式写入(BulkInsert)两种模式。绝大多数用户在最初接触Milvus的时候,都会选择流式写入,这种方式实时性较好,同时也避免了批式写入小文件带来的Compaction压力。如果有大量离线写入的场景,建议使用BulkInsert,原因是BulkInsert不会对查询性能造成太大的影响,并且也大大减少了流式写入对消息队列产生的压力。如何合理选择流式还是批式写入呢:
作为数据库,Milvus支持了删除,标量过滤, TimeTravel等高级特性。如果不了解底层原理,使用这些高级功能可能会对稳定性和性能造成比较严重的影响,以下是一些使用注意事项:
经验5 - 部署监控并观察集群情况
可观测性是用户在生产环境落地非常重要的一部分,Milvus 2.2 重新梳理监控指标并且校正了指标的正确性,我们强烈建议你的生产集群部署监控并且在上线之前进行进行性能测试。
除了每个节点的CPU使用率,内存使用量信息,以下是一些建议你关注的监控指标:
Proxy
查询延迟: milvus_proxy_sq_latency/milvus_proxy_collection_sq_latency
写入/删除延迟: milvus_proxy_mutation_latency
写入流量: milvus_proxy_receive_bytes_count
查询返回流量: milvus_proxy_send_bytes_count
QueryNode
加载的数据量: milvus_querynode_entity_num
查询请求排队时间:milvus_querynode_sq_queue_latency
单个Segment的查询时间: milvus_querynode_sq_segment_latency
IndexNode
构建索引的时间: milvus_indexnode_build_index_latency
DataNode
Flush花费的时间: milvus_datanode_save_latency
Compaction花费的时间:milvus_datanode_compaction_latency
经验6 - 一些常见的参数调整
想要使得Milvus跑的更快更稳,针对自己的使用场景,硬件资源情况进行一些定制化的调整自然是不可避免的,你可以从了解以下参数开始:
Segment大小: Segment大小越大,查询性能越好,构建索引越慢,负载越不容易均衡。Milvus默认选择512M Segment大小主要考虑到内存比较少的机型。对于内存在8G-16G的用户,建议Segment大小调整到1024M,16G以上的机型可以调整到2G。
Segment seal portion: 当Growing Segment达到Segment大小*seal portion后,流式数据就会被转换为批数据。通常情况下建议Growing segment的大小控制在100-200M左右,调小这个值有助于降低流式写入场景下的查询延迟。
DataNode Segment SyncPeriod: Milvus会定时将数据Sync到对象存储,Sync越频繁故障恢复速度越快,但过于频繁的sync会导致Milvus生产大量小文件,给对象存储造成较大压力。
Quota相关的参数: 目前支持限制Milvus的写入,删除流量,查询的QPS,以及内存的保护,当触发性能问题时,也要观察是否是因为触发了相应的限流。
结尾
强烈推荐更新社区的LTS版本,包含了大量性能优化和稳定性Fix, 凝结了社区几百名贡献者的心血,大部分用户踩到的坑其实新版本都已经修复解决。如果你对云计算,分布式,数据库,向量检索,高性能计算这些领域感兴趣,欢迎加入Milvus社区和社区背后的公司Zilliz,以下是社区正在推进的一些项目:
1)接入Google 的ScaNN索引,优化Milvus向量执行引擎Knowhere的性能
2)10亿向量的查询/加载性能优化
3)支持RangeSearch
4)改进Milvus的标量执行引擎,支持更加复杂的标量数据类型,降低标量的内存开销。
5)改进Partition算法,支持动态增加/减少partition个数
6)支持Faiss,HNSW,Milvus 1.0迁移Milvus 2.0
7) Cpp,Rust,Restful API的开发和完善
....
如果你在使用Milvus或者调优的过程中遇到任何苦难,也欢迎来社区开issue或者加入我们的Milvus微信交流群。
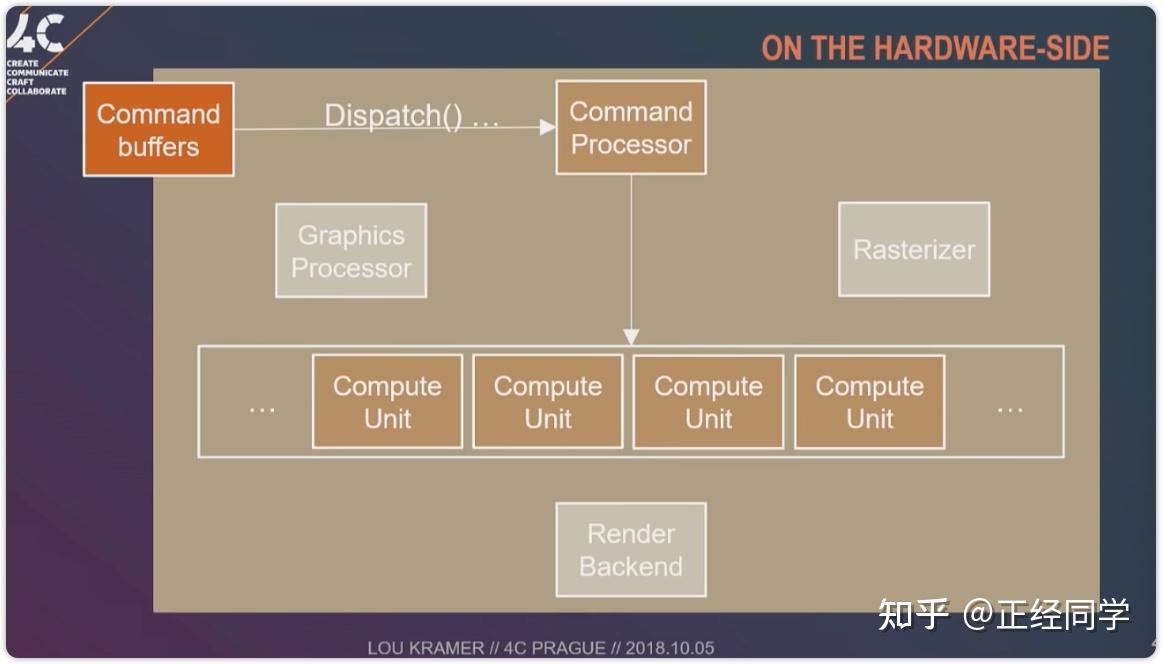
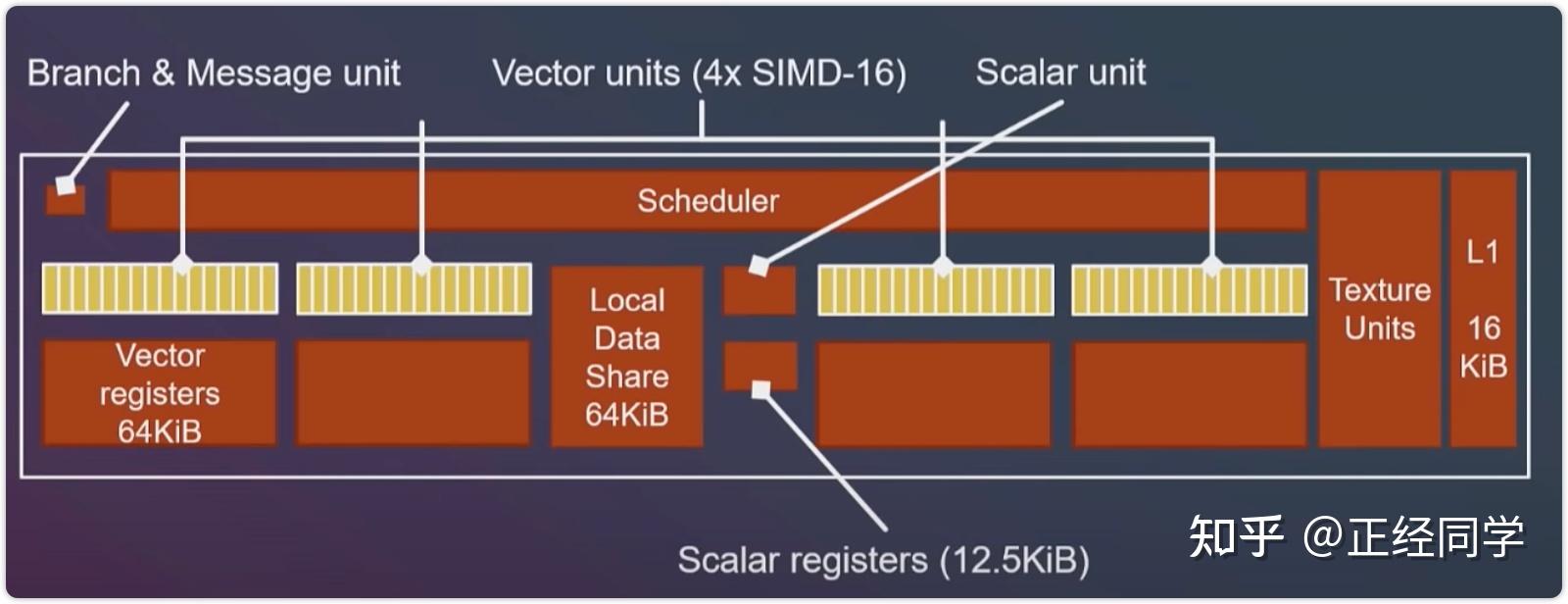
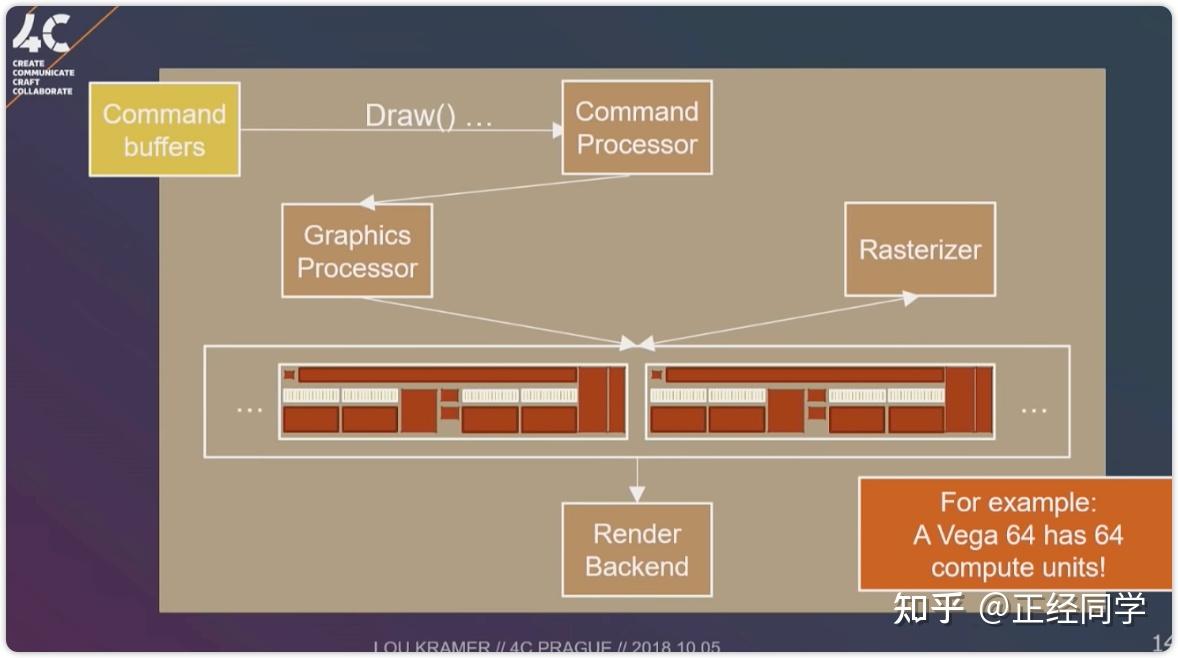
Enjoy it!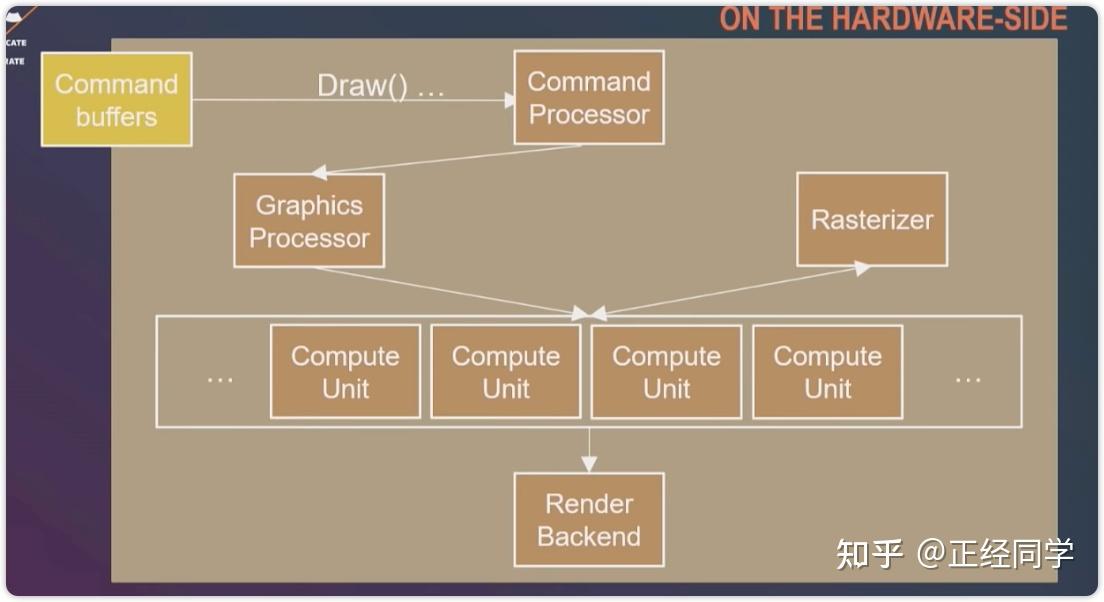
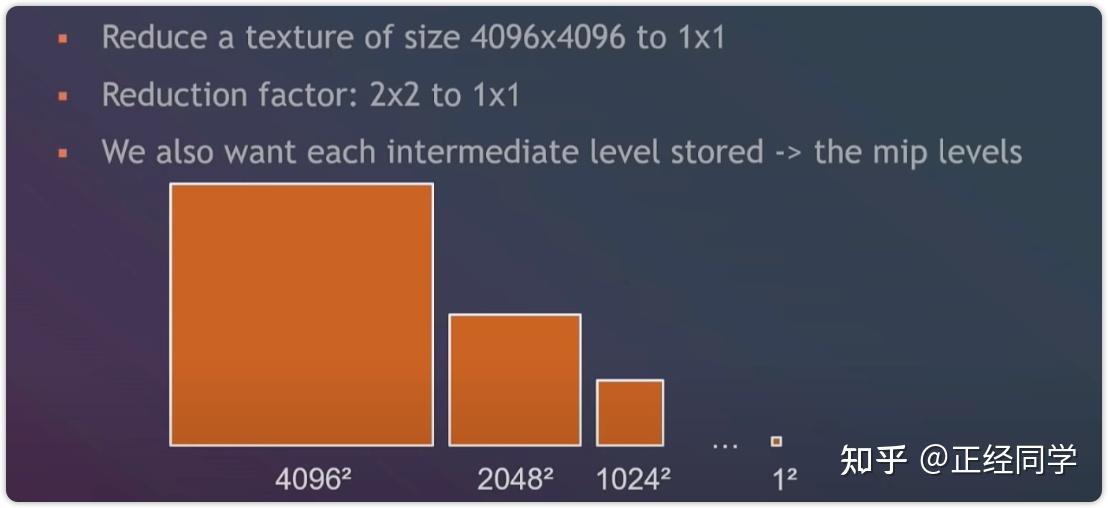
#pragma kernel CSMain // CSMain是执行的compute kernel函数名
RWTexture2D<float4> Result;// CS中可读写的纹理
[numthreads(8,8,1)]// 线程组中的线程数
void CSMain (uint3 id : SV_DispatchThreadID)
{
// TODO: insert actual code here!
Result[id.xy]=float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}var mainKernel=_filterComputeShader.FindKernel(_kernelName);
ComputeShader.GetKernelThreadGroupSizes(mainKernel, out uint xGroupSize, out uint yGroupSize, out _);
cmd.DispatchCompute(ComputeShader, mainKernel, 4, 3, 2);




摘要:通常跑批加工场景下,都是大数量做关联操作,通常不建议使用索引。有些时候因为计划误判导致使用索引的可能会导致严重的性能问题。本文从一个典型的索引导致性能的场景重发,剖析此类问题的特征,定位方法和解决方法
WITH
/**
etl_116583_7960703_994644
**/
LOADABLE as (select "boq_rel_type_id","to_pu_id","to_version","cycle_id",
"part_offset_flag","to_boq_id","descr","from_contract_id",
"from_version","from_pu_id","ss_id","to_contract_id",
"from_boq_id","enable_flag","last_update_date"
from (SELECT /*+ PARALLEL(4)*/
BOQ_REL.FROM_BOQ_ID,
BOQ_REL.TO_BOQ_ID,
BOQ_REL.FROM_PU_ID,
BOQ_REL.TO_PU_ID,
BOQ_REL.PART_OFFSET_FLAG,
BOQ_REL.DESCR,
BOQ_REL.SS_ID,
BOQ_REL.CYCLE_ID,
NVL(BOQ_REL.FROM_VERSION, 'SNULL') FROM_VERSION,
NVL(BOQ_REL.TO_VERSION, 'SNULL') TO_VERSION,
BOQ_REL.LAST_UPDATE_DATE,
FROM_CON.CONTRACT_ID AS FROM_CONTRACT_ID,
TO_CON.CONTRACT_ID AS TO_CONTRACT_ID,
CLA.CLASS_ID AS BOQ_REL_TYPE_ID,
BOQ_REL.ENABLE_FLAG
FROM (SELECT A.FROM_BOQ_ID,
A.TO_BOQ_ID,
A.FROM_PU_ID,
A.TO_PU_ID,
A.FROM_CONTRACT_NUMBER,
A.TO_CONTRACT_NUMBER,
A.BOQ_REL_TYPE_CODE,
A.PART_OFFSET_FLAG,
A.DESCR,
A.SS_ID,
A.FROM_VERSION,
A.TO_VERSION,
A.LAST_UPDATE_DATE,
A.CYCLE_ID,
A.ENABLE_FLAG,
DECODE(A.SS_ID, 2820, 2600, A.SS_ID) SS_ID_TMP,
ROW_NUMBER() OVER(PARTITION BY FROM_BOQ_ID, TO_BOQ_ID, FROM_PU_ID, TO_PU_ID, FROM_CONTRACT_NUMBER, TO_CONTRACT_NUMBER, BOQ_REL_TYPE_CODE, FROM_VERSION, TO_VERSION
ORDER BY DECODE(A.SS_ID, 2820, 1, 2600, 2, 3)) RN
FROM LDB_MD_BOQ_REL A) BOQ_REL,
(SELECT CONTRACT_ID,
HW_CONTRACT_NUM,
SS_ID
FROM DWI_MD_CONTRACT
WHERE CONTRACT_ID IS NOT NULL
AND END_TIME=TO_DATE('4712-12-31', 'YYYY-MM-DD')) FROM_CON,
(SELECT CONTRACT_ID,
HW_CONTRACT_NUM,
SS_ID
FROM DWI_MD_CONTRACT
WHERE CONTRACT_ID IS NOT NULL
AND END_TIME=TO_DATE('4712-12-31', 'YYYY-MM-DD')) TO_CON,
(SELECT CLASS_ID,
CODE,
CLASS_TYPE_ID,
SS_ID
FROM DWI_MD_CLASS
WHERE CLASS_TYPE_ID=193) CLA
WHERE BOQ_REL.RN=1
AND BOQ_REL.FROM_CONTRACT_NUMBER=FROM_CON.HW_CONTRACT_NUM
AND BOQ_REL.SS_ID=FROM_CON.SS_ID
AND BOQ_REL.TO_CONTRACT_NUMBER=TO_CON.HW_CONTRACT_NUM
AND BOQ_REL.SS_ID=TO_CON.SS_ID
AND BOQ_REL.BOQ_REL_TYPE_CODE=CLA.CODE
AND BOQ_REL.SS_ID_TMP=CLA.SS_ID
) t
),
BEFORE_TARGET as (select "from_contract_id","from_pu_id","ss_id","from_boq_id","from_version","to_version",
"crt_cycle_id","to_pu_id","to_boq_id","del_flag","last_upd_cycle_id","last_update_date",
"descr","enable_flag","crt_job_instance_id","dq_improve_flag","upd_job_instance_id",
"to_contract_id","part_offset_flag","boq_rel_type_id"
from (SELECT /*+PARALLEL(4)*/
FROM_BOQ_ID,
TO_BOQ_ID,
FROM_PU_ID,
TO_PU_ID,
FROM_CONTRACT_ID,
TO_CONTRACT_ID,
BOQ_REL_TYPE_ID,
PART_OFFSET_FLAG,
DESCR,
SS_ID,
CRT_CYCLE_ID,
LAST_UPD_CYCLE_ID,
DEL_FLAG,
DQ_IMPROVE_FLAG,
CRT_JOB_INSTANCE_ID,
UPD_JOB_INSTANCE_ID,
NVL(FROM_VERSION, 'SNULL') FROM_VERSION,
NVL(TO_VERSION, 'SNULL') TO_VERSION,
LAST_UPDATE_DATE,
ENABLE_FLAG
FROM DWI_MD_BOQ_REL
) t
),
CDC as (select LOADABLE."ss_id",LOADABLE."from_version",LOADABLE."from_boq_id",
LOADABLE."part_offset_flag",LOADABLE."from_pu_id",
case when BEFORE_TARGET.BOQ_REL_TYPE_ID is null and BEFORE_TARGET.FROM_BOQ_ID is null
and BEFORE_TARGET.FROM_CONTRACT_ID is null and BEFORE_TARGET.FROM_PU_ID is null
and BEFORE_TARGET.FROM_VERSION is null
and BEFORE_TARGET.TO_BOQ_ID is null and BEFORE_TARGET.TO_CONTRACT_ID is null
and BEFORE_TARGET.TO_PU_ID is null and BEFORE_TARGET.TO_VERSION is null
then 1
else 3
end as "change_code",
LOADABLE."to_version",LOADABLE."boq_rel_type_id",
LOADABLE."from_contract_id",LOADABLE."to_contract_id",
LOADABLE."descr",LOADABLE."last_update_date",
LOADABLE."to_pu_id",LOADABLE."enable_flag",LOADABLE."cycle_id",
LOADABLE."to_boq_id"
from LOADABLE
left join BEFORE_TARGET on LOADABLE.BOQ_REL_TYPE_ID=BEFORE_TARGET.BOQ_REL_TYPE_ID
and LOADABLE.FROM_BOQ_ID=BEFORE_TARGET.FROM_BOQ_ID and LOADABLE.FROM_CONTRACT_ID=BEFORE_TARGET.FROM_CONTRACT_ID
and LOADABLE.FROM_PU_ID=BEFORE_TARGET.FROM_PU_ID and LOADABLE.FROM_VERSION=BEFORE_TARGET.FROM_VERSION
and LOADABLE.TO_BOQ_ID=BEFORE_TARGET.TO_BOQ_ID and LOADABLE.TO_CONTRACT_ID=BEFORE_TARGET.TO_CONTRACT_ID
and LOADABLE.TO_PU_ID=BEFORE_TARGET.TO_PU_ID and LOADABLE.TO_VERSION=BEFORE_TARGET.TO_VERSION
),
TFM_FILTER_DATA_TARGET_OUTPUT_U as (select CDC."to_pu_id",CDC."boq_rel_type_id",CDC."ss_id",
Current_Timestamp() as "dw_last_update_date",CDC."to_version",
CDC."from_version",20230104000000 as "last_upd_cycle_id",
CDC."from_contract_id",CDC."last_update_date",CDC."descr",
'N' as "del_flag",CDC."from_boq_id",CDC."to_boq_id",
CDC."enable_flag",CDC."from_pu_id",-1 as "upd_job_instance_id",
'N' as "dq_improve_flag",CDC."to_contract_id",
CDC."part_offset_flag"
from CDC where CDC.change_code=3
)
update DWI_MD_BOQ_REL TARGET_U
set "dq_improve_flag"=TFM_FILTER_DATA_TARGET_OUTPUT_U."dq_improve_flag",
"dw_last_update_date"=TFM_FILTER_DATA_TARGET_OUTPUT_U."dw_last_update_date",
"upd_job_instance_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."upd_job_instance_id",
"descr"=TFM_FILTER_DATA_TARGET_OUTPUT_U."descr",
"part_offset_flag"=TFM_FILTER_DATA_TARGET_OUTPUT_U."part_offset_flag",
"last_update_date"=TFM_FILTER_DATA_TARGET_OUTPUT_U."last_update_date",
"del_flag"=TFM_FILTER_DATA_TARGET_OUTPUT_U."del_flag",
"last_upd_cycle_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."last_upd_cycle_id",
"enable_flag"=TFM_FILTER_DATA_TARGET_OUTPUT_U."enable_flag",
"ss_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."ss_id"
from TFM_FILTER_DATA_TARGET_OUTPUT_U
where TARGET_U."boq_rel_type_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."boq_rel_type_id"
and TARGET_U."to_version"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_version"
and TARGET_U."to_version"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_version"
and TARGET_U."to_pu_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_pu_id"
and TARGET_U."to_pu_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_pu_id"
and TARGET_U."to_contract_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_contract_id"
and TARGET_U."to_contract_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_contract_id"
and TARGET_U."to_boq_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_boq_id"
and TARGET_U."to_boq_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."to_boq_id"
and TARGET_U."from_version"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_version"
and TARGET_U."from_version"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_version"
and TARGET_U."from_pu_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_pu_id"
and TARGET_U."from_pu_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_pu_id"
and TARGET_U."from_contract_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_contract_id"
and TARGET_U."from_contract_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_contract_id"
and TARGET_U."from_boq_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_boq_id"
and TARGET_U."from_boq_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."from_boq_id"
and TARGET_U."boq_rel_type_id"=TFM_FILTER_DATA_TARGET_OUTPUT_U."boq_rel_type_id"
;

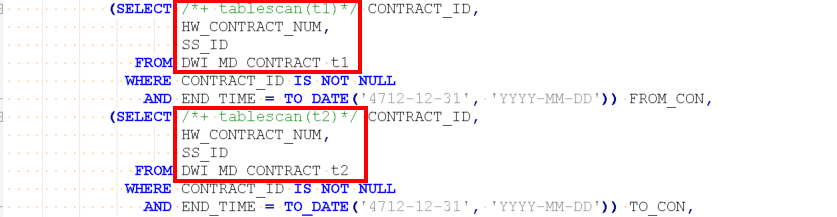
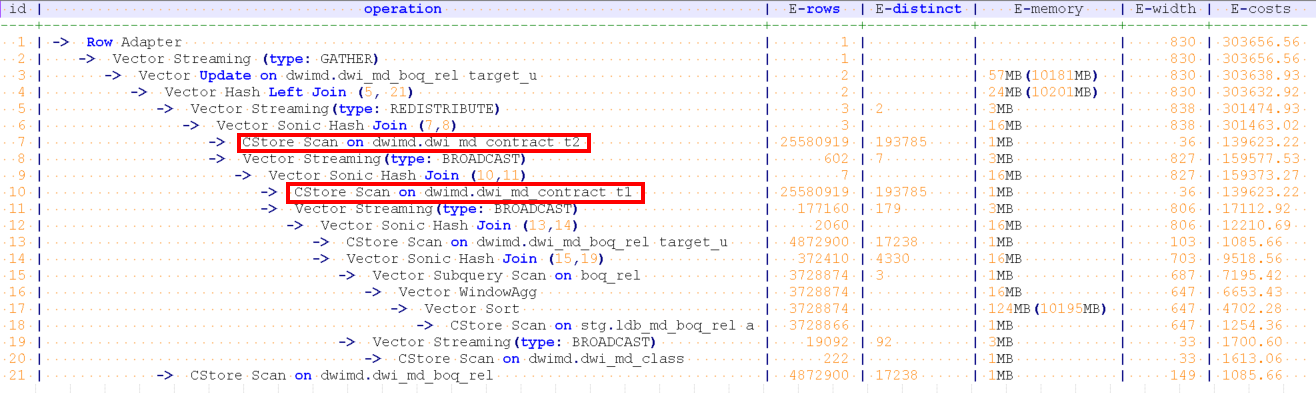
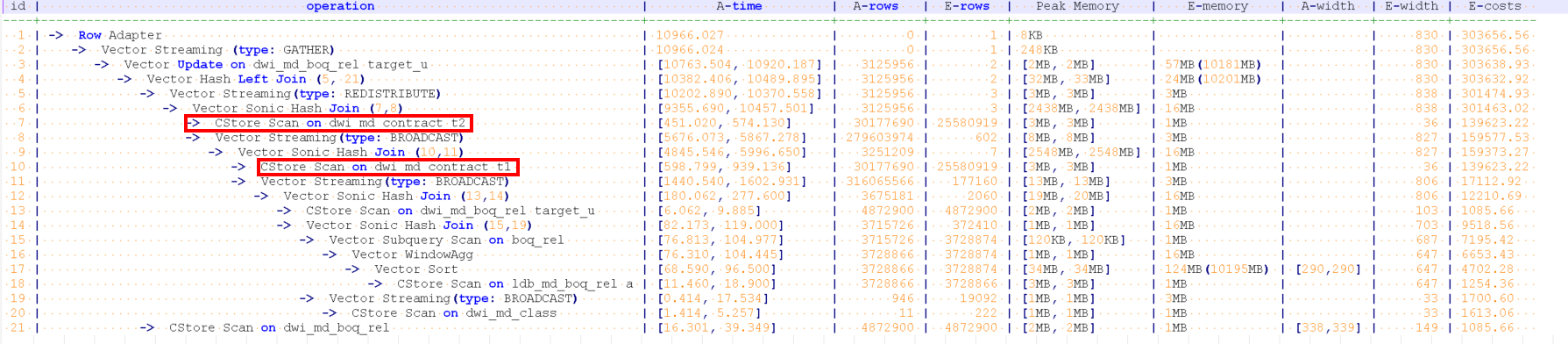
class S1 {
public:
int a[100]; // 400 bytes. first byte at 0, last byte at 399
int b; // 4 bytes. first byte at 400, last byte at 403
int ReadB() {return b;}
};
class S2 {
public
int b; // 4 bytes. first byte at 0, last byte at 3
int ReadB() {return b;}
int a[100]; // 400 bytes. first byte at 4, last byte at 403
};
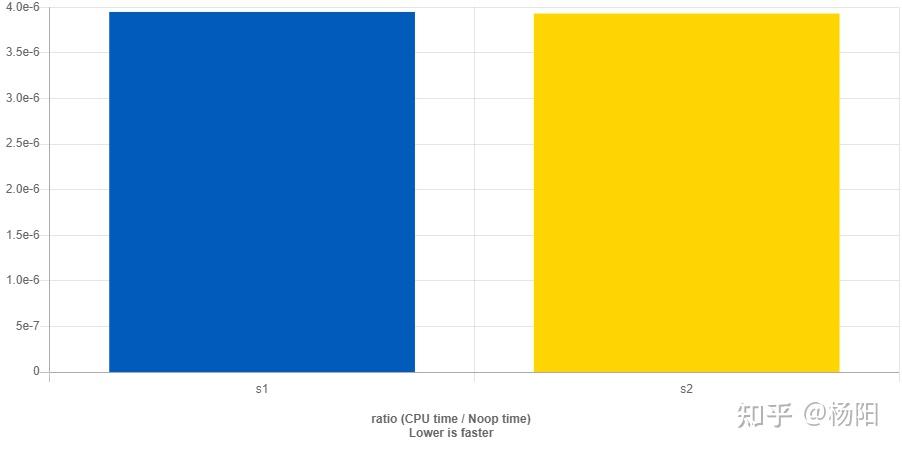
class S3 {
public:
int a;
int b;
int Sum1() {return a + b;}
};
int Sum2(S3 * p) {return p->a + p->b;}
int Sum3(S3 & r) {return r.a + r.b;}
int main() {
S3 s;
s.Sum1();
return 0;
}
S3::Sum1():
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-8], rdi
mov rax, QWORD PTR [rbp-8]
mov edx, DWORD PTR [rax]
mov rax, QWORD PTR [rbp-8]
mov eax, DWORD PTR [rax+4]
add eax, edx
pop rbp
ret
Sum2(S3*):
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-8], rdi
mov rax, QWORD PTR [rbp-8]
mov edx, DWORD PTR [rax]
mov rax, QWORD PTR [rbp-8]
mov eax, DWORD PTR [rax+4]
add eax, edx
pop rbp
ret
Sum3(S3&):
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-8], rdi
mov rax, QWORD PTR [rbp-8]
mov edx, DWORD PTR [rax]
mov rax, QWORD PTR [rbp-8]
mov eax, DWORD PTR [rax+4]
add eax, edx
pop rbp
ret
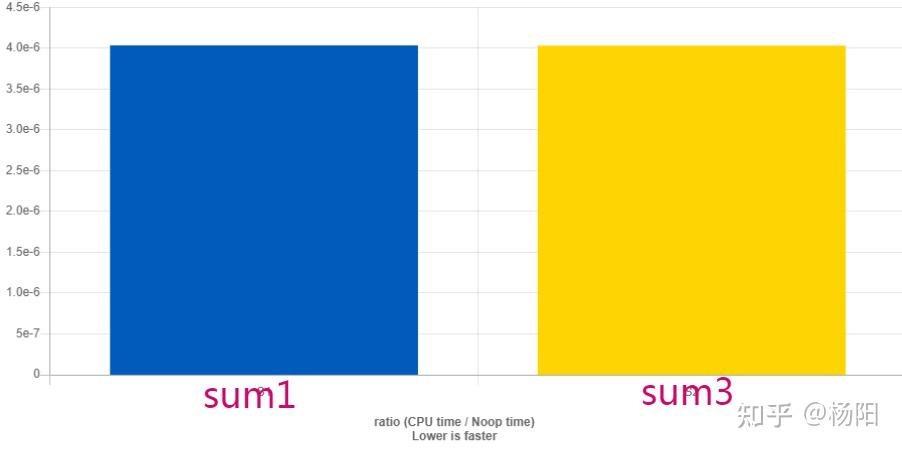
class C0 {
public:
virtual void f(){}
};
class C1 : public C0 {
public:
virtual void f(){}
};
void g() {
C1 obj1;
C0 * p = & obj1;
p->f(); // Virtual call to C1::f
}
#include <iostream>
using std::cout;
using std::endl;
struct {
uint32_t year:23;
uint32_t day:5;
uint32_t month:4;
} typedef Bitfield;
int main() {
Bitfield date = {2020, 13, 12};
cout << "sizeof Bitfield: " << sizeof(date) << " bytes\
";
cout << "date: " << date.day << "/"
<< date.month << "/" << date.year << endl;
return EXIT_SUCCESS;
}
sizeof Bitfield: 4 bytes
date: 13/12/2020
struct 和一个内置类型变量组成的 union 类型对象来解决。uint32_t 成员。这样可以节省一次访问数据的时间,而不是对三个成员分别重复同样的操作。#include <iostream>
using std::cout;
using std::endl;
union BitfieldFast{
struct {
uint32_t year:23;
uint32_t day:5;
uint32_t month:4;
};
uint32_t ydm;
};
int main() {
BitfieldFast date_f{};
date_f.ydm = 2020 | (13 << 23) | (12 << 28);
cout << "sizeof BitfieldFast: " << sizeof(date_f) << " bytes\
";
cout << "date: " << date_f.day << "/"
<< date_f.month << "/" << date_f.year << endl;
return EXIT_SUCCESS;
}
sizeof BitfieldFast: 4 bytes
date: 13/12/2020
struct Bitfield {
int a:4;
int b:2;
int c:2;
};
Bitfield x;
int A, B, C;
x.a = A;
x.b = B;
x.c = C;
union Bitfield {
struct {
int a:4;
int b:2;
int c:2;
};
char abc;
};
Bitfield x;
int A, B, C;
x.abc = A | (B << 4) | (C << 6);
x.abc = (A & 0x0F) | ((B & 3) << 4) | ((C & 3) <<6 );
class vector { // 2-dimensional vector
public:
float x, y; // x,y coordinates
vector() {} // default constructor
vector(float a, float b) {x = a; y = b;} // constructor
vector operator + (vector const & a) { // sum operator
return vector(x + a.x, y + a.y);} // add elements
};
vector a, b, c, d;
a = b + c + d; // makes intermediate object for (b + c)
a.x = b.x + c.x + d.x;
a.y = b.y + c.y + d.y;
int Multiply (int x, int m) {
return x * m;}
template <int m>
int MultiplyBy (int x) {
return x * m;}
int a, b;
a = Multiply(10,8);
b = MultiplyBy<8>(10);
// Example 7.47b. Compile-time polymorphism with templates
// Place non-polymorphic functions in the grandparent class:
class GrandParent {
public:
void NotPolymorphic();
};
// Any function that needs to call a polymorphic function goes in the
// parent class. The child class is given as a template parameter:
template <typename Child>
class Parent : public GrandParent {
public:
void Hello() {
cout << "Hello ";
(static_cast<Child*>(this))->Disp();
}
};
class Child1 : public Parent<Child1> {
public:
void Disp() {
cout << 1;
}
};
class Child2 : public Parent<Child2> {
public:
void Disp() {
cout << 2;
}
};
void test () {
Child1 Object1; Child2 Object2;
Child1 * p1;
p1 = &Object1;
p1->Hello(); // Writes "Hello 1"
Child2 * p2;
p2 = &Object2;
p2->Hello(); // Writes "Hello 2"
}
创客课程开发的每个主题课程需要基于现实情景,设置学习探究任务,通过问题研究、任务...
创客空间建设 能够给人们分享各种乐趣,通过电脑,技术,科学,艺术结合,设计创造一...
在了解创客教育之前,我们首先了解下何为创客。创客是一群喜欢或享受创新的人。创客跨...
STEAM教育是对传统教育的提升,它是基于自然学校方式的功能性框架,可以适合各类...