从前端,中间表示,到后端,有没有什么比较重要的技术进步是鲸书,龙书(第二版),《现代体系结构优化编译器》,《garbage collection handbook》这些书都没有提到的呢?
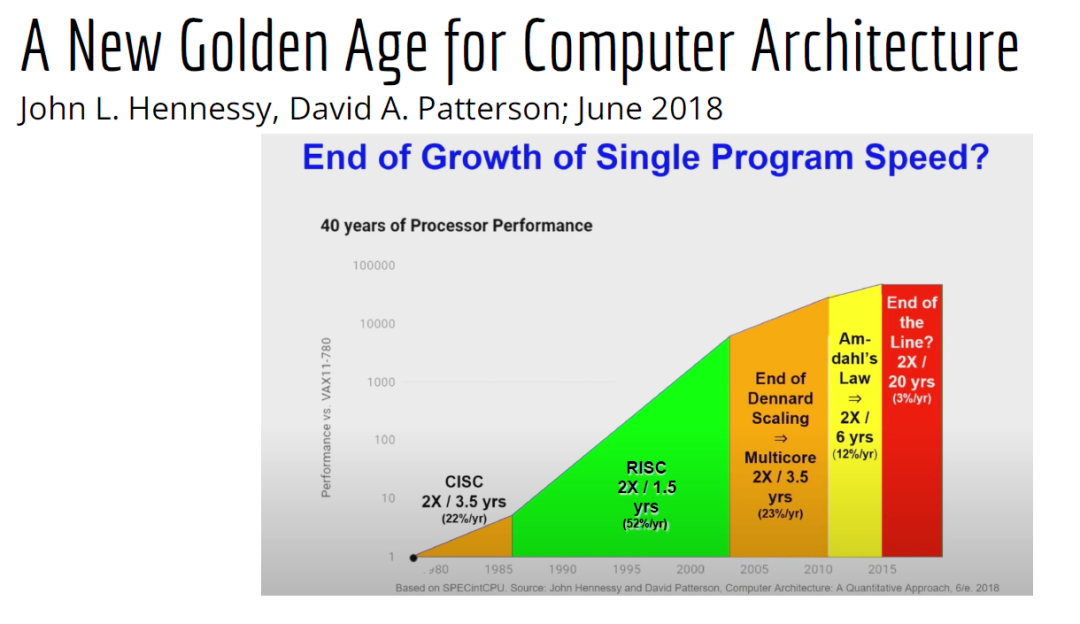
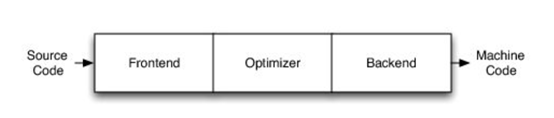
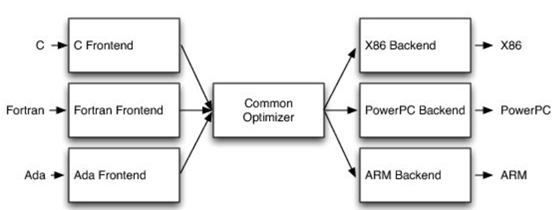
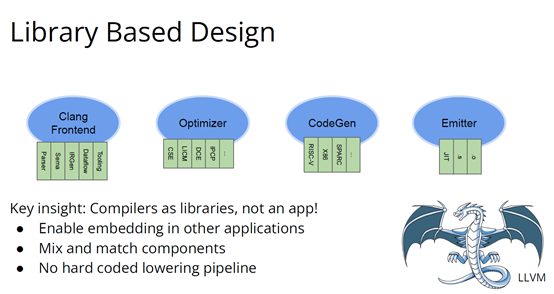
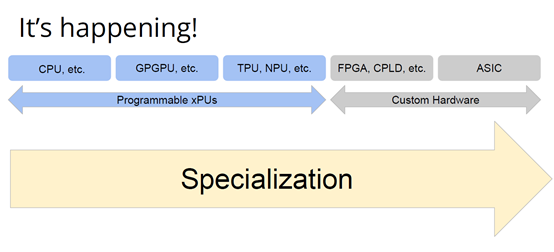
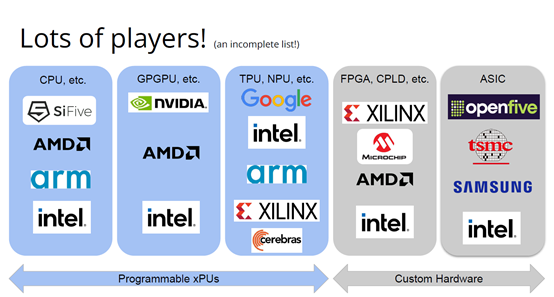
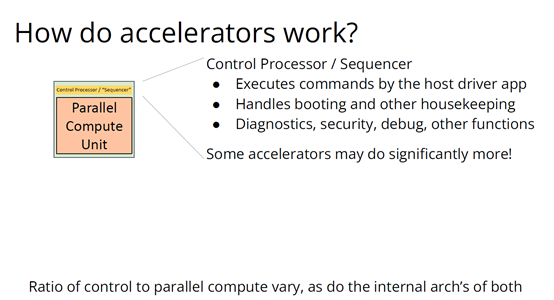
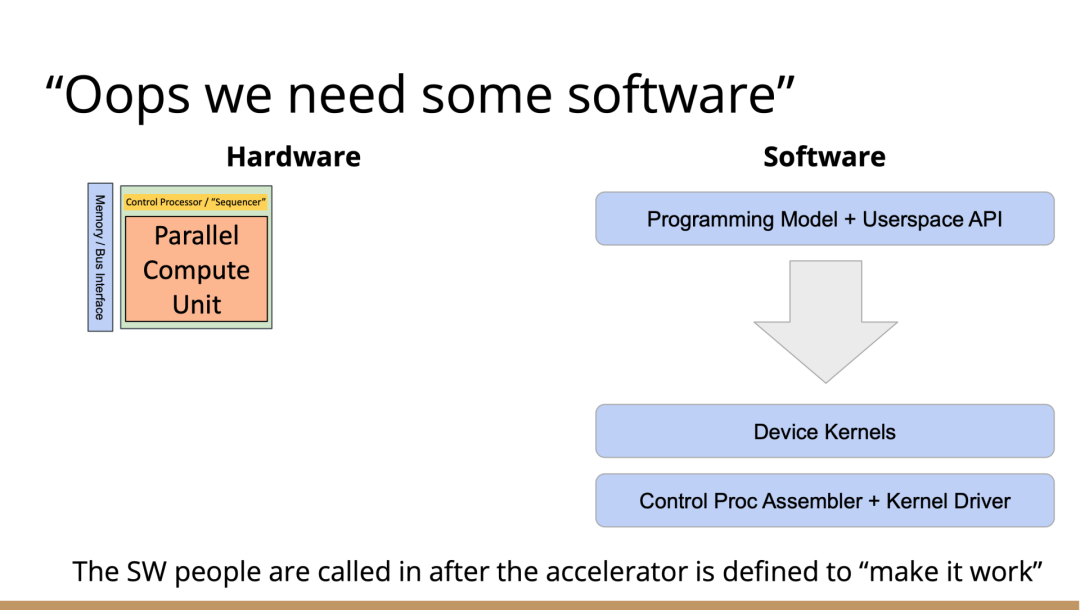
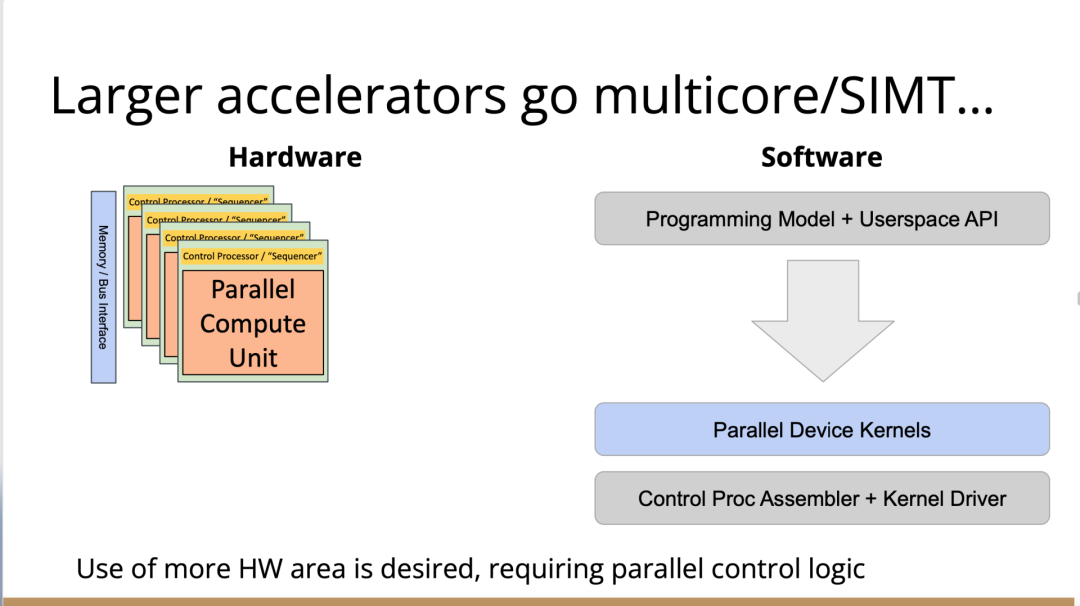
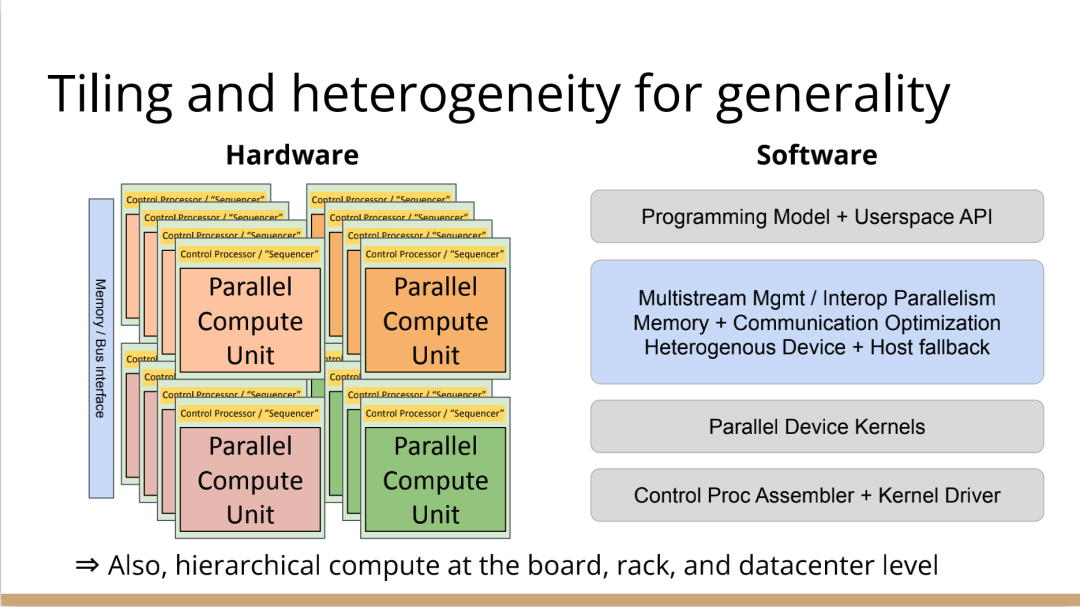
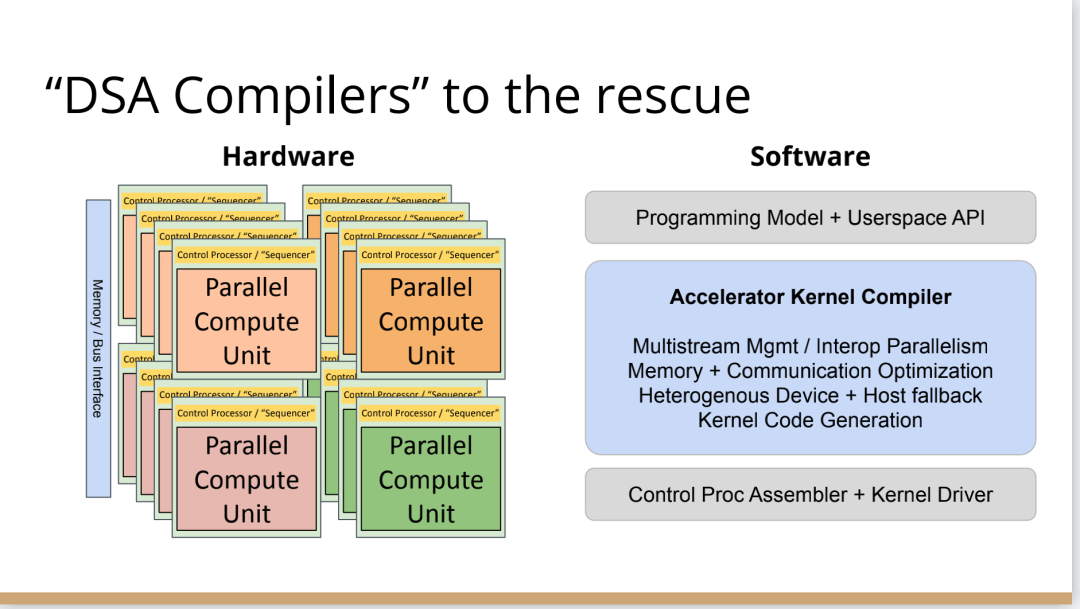
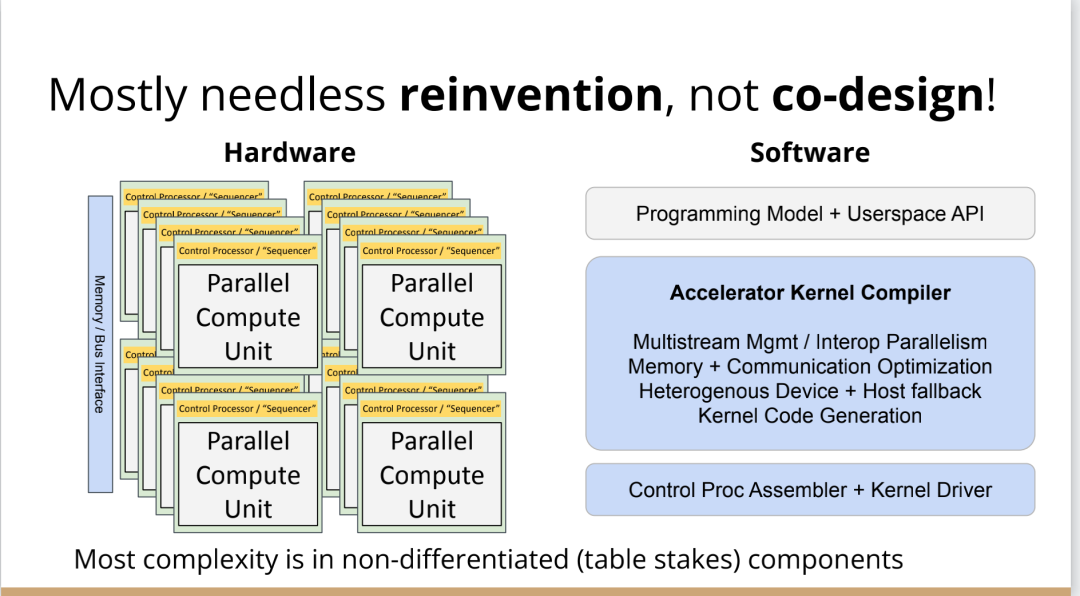
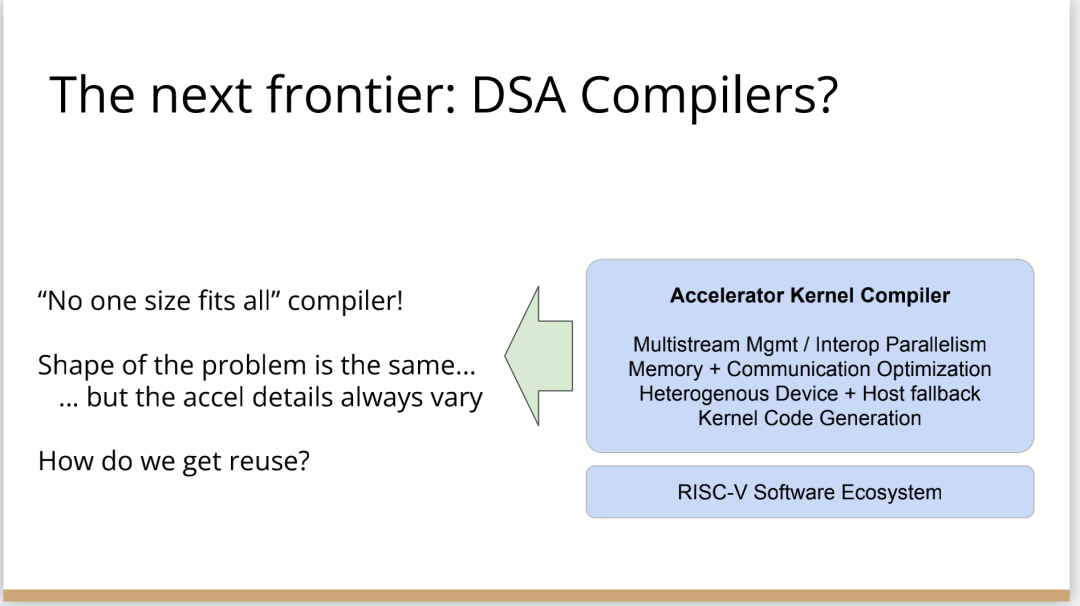
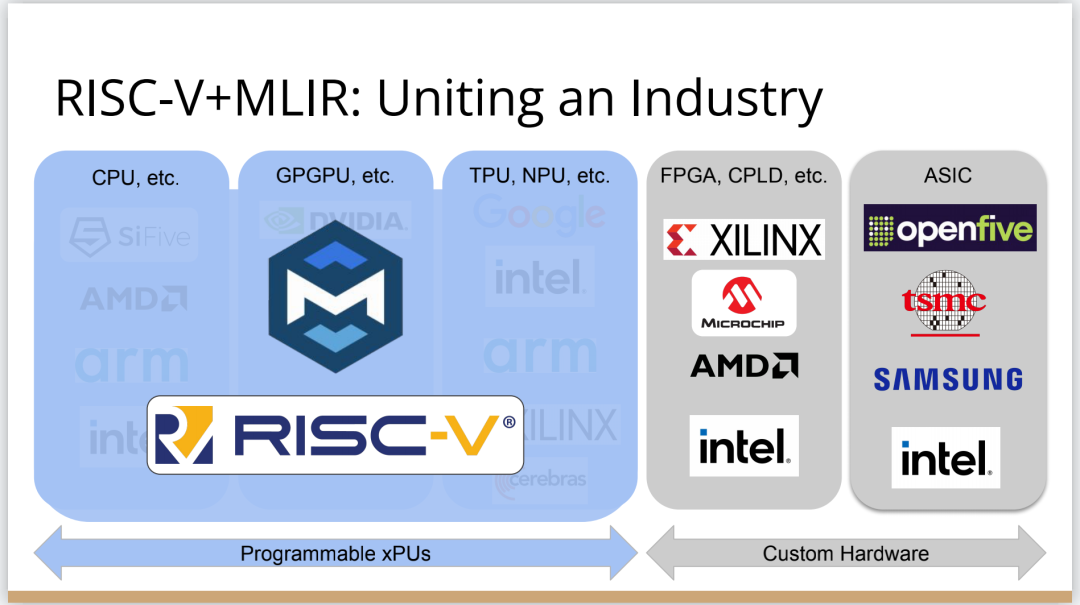
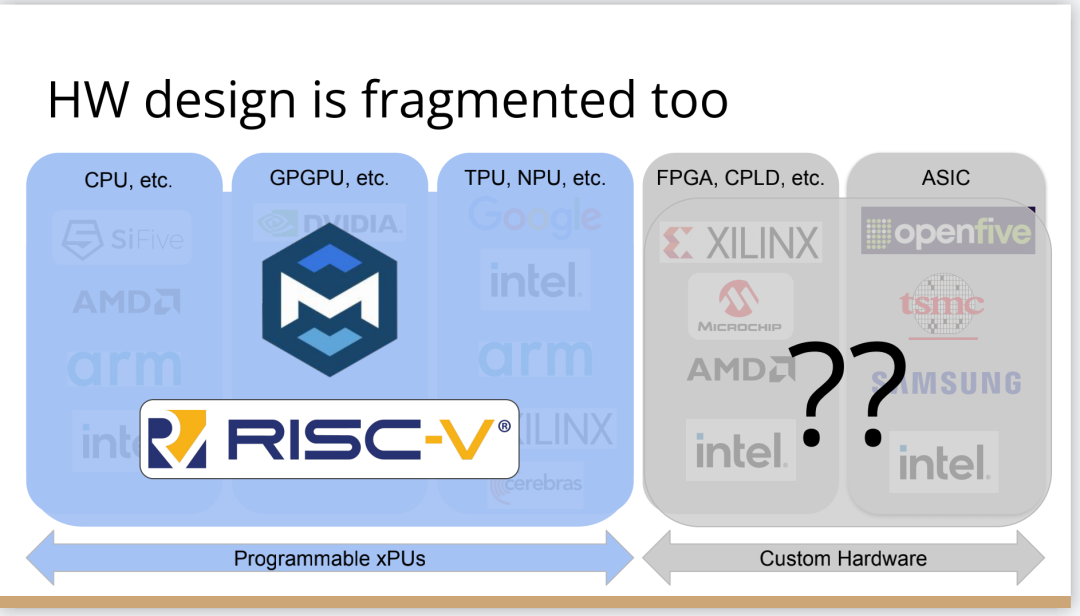
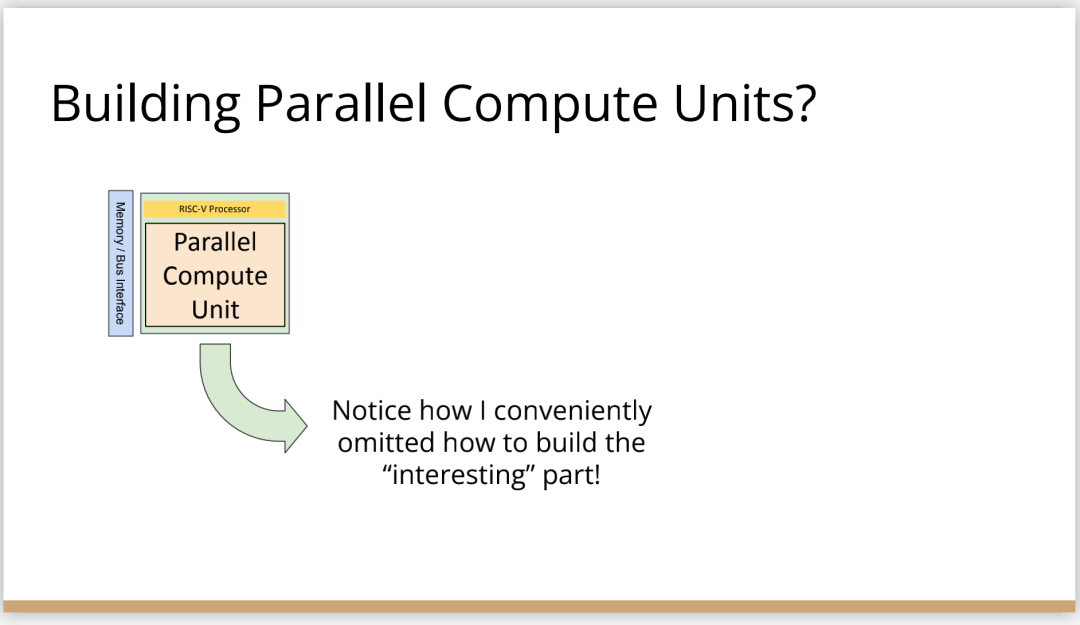
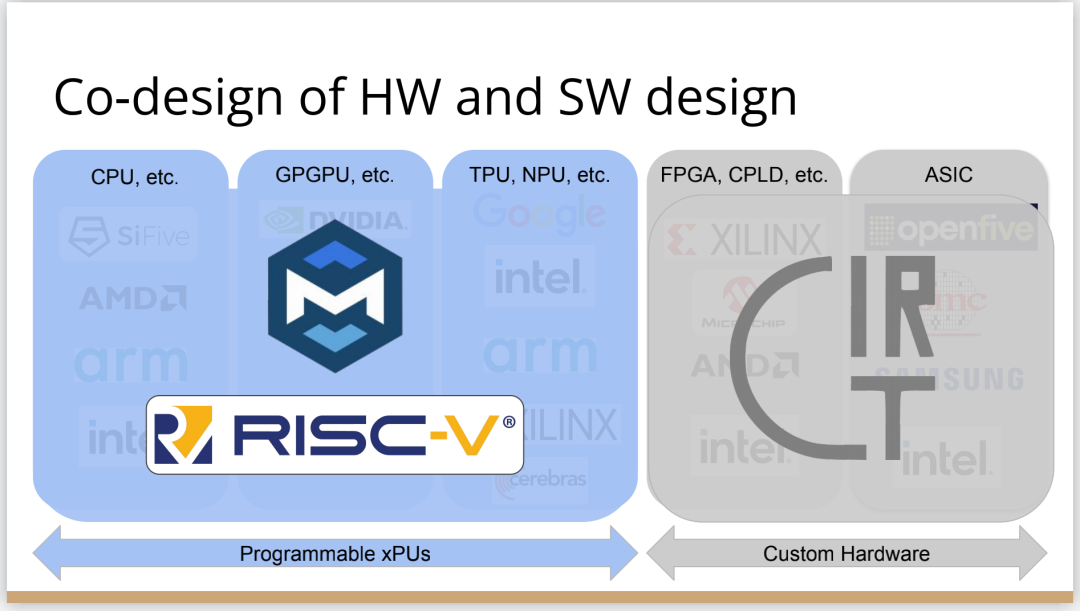
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.78.2542&rep=rep1&type=pdf 这篇论文可以看一下 编译器实在是太过悠久,也太过重要,无数人都在研究,于是编译器的前端技术几乎都被前人榨干了,相当成熟了。现在的编译器的主要卖点就是功率消耗与优化,比如编译时候所需的时间、空间以及所执行的程序优化后的表现等。而这里所说的功率消耗与优化,根本没有办法榨干,如同人的欲望一样,永远想更好更快(如F1追求极速一样,这就是本质上的一种追求)。而现在编译器的优化方面,在我的阅历中,没有那种石破天惊的优化技术(如果出现了,我觉得你们都一定能听到,因为这个不拿奖真的说不过去)。做优化其实是一件苦活,有时候甚至是一件体力活,同时也是一门玄学,无法摸到却又真实存在。就目前而言,要达到非常好的优化,很多时候只有与硬件一起配合,这是没有办法的事情(也许抽象一个无限接近于底层性能表现的VM可以去办到通用吧,这也是很多研究VM的想法,不断提高VM的性能表现),于是可以发现能自己做硬件的公司都有自己的编译器部门,这不是编译器赚钱与否的问题,是不搞不行,能开编译器部门的公司几乎没有想过靠编译器部门赚钱,是养着这群人。编译器最近因为LLVM的出现又火了一下,LLVM IR是我觉得很不错的一种中间表示,至少让我眼前是一亮的感觉。LLVM的目标也很伟大,但是我觉得Apple算是目前LLVM实现目标的最佳孵化场合了。 先主要说三个: 它们的特点是:思想/技术上大多都是已有的,但是都有亮点 像LLVM,Link-time、Run-time、Compiler-time多阶段优化,不是很新潮的思想;各种基于CFG、SSA的分析、优化,在传统的Fortran/C++中几乎用到极致;LLVM的IR算一种typed SSA,函数式语言的编译中也早已采用;与它定位类似的Stanford SUIF也挺通用的。它的伟大之处就在于,能把已有技术很好地整合到一个系统,比同类(如SUIF)更有野心,并且在这个框架之下,能方便不断融合新的技术——这些年不少论文的成果都被整合到LLVM中。我觉得这是一个大的进步。 再来说动态语言的编译,以JavaScript为代表。新世纪以来(主要是最近五六年),JS引擎可谓突飞猛进(最近有所下降。。)。它们在技术上进步大么?V8的hidden class + inline caching技术起源于Smalltalk,SpiderMonkey的nan-boxing来自Lua JIT,而JIT、GC等技术有教科书式的JVM(当然也有其他历史积累)。针对动态语言的Type specialization(动态的type feedback,静态的type inference)算是这些年发展比较多的,将来会更多地采用异构分析——将两者结合。 动态语言的实现,应该说是有所进步的,工业界+学术界都有比较强的驱动力,相信会有更多的技术进步。。 刚刚说到type inference,有些同学会说:函数式语言不早有了。由此引出第三个话题,program analysis。讲LLVM时也说到,传统的Fortran/C++用到很多Program Analysis(Data flow analysis, Pointer analysis,等等),函数式语言中加一个Type Inference,而且它们已经比较成熟,成熟到快做不下去了。。于是呢,这些年有个趋势:把老技术移植到新语言,面向对象如Java,动态如JavaScript。当然这个移植也没那么简单,,另外传统的算法层面,也是有一些进步的。。 PS: 在这方面比较专业。。 ------------------- 待补充:Certified compiler,Multicore相关,函数式语言相关,GPU相关。。各种。。 可以补充一下函数式语言的。。。 我先赶俩文章。。 个人觉得几点是实打实的进步。 前端: 架构: 传统编译器前后端架构几乎都要被LLVM这样的由中间表示层进行强分离的模式替代,LLVM和传统中间表示层有巨大的不同,简单的讲LLVM的中间表示层IR实现了一个强大的可扩展的底层语言规范,范围不仅是LLVM reference manual那里的内容。这个设计的一大优点是非常强大的横向和纵向的扩展性,异构计算下厂商可以直接拓展llvm的IR, 同时极大利用已经存在的前端优化pass和大量的后端优化pass,我从来没有在其它编译器中看到可以实现这样的拓展性的能力。 后端: 苹果从x86切换arm结构实现了一次告诉行驶列车换轮胎的把戏,这其实是一次工具链上真正的系统工程级别的成功技术实践。这东西看起来简单但是想想工程难度得工程量都感觉不可思议,如果不是苹果完全吃透两种芯片架构+系统+工具链技术是不可能做到的。 作者|Chris Lattner 翻译|胡燕君、周亚坤 摩尔定律失效论的讨论与日俱增,2018年,图灵奖获得者 John Hennessey 和 David Patterson 在一次演讲上更是直言,几十年来的 RISC(精简指令集)和 CISC(复杂指令集)孰优孰劣之争可以终结了,新一轮计算机架构的黄金时代已经到来,为此,他们在2019年的 ACM 期刊上发表了一篇文章里作专门论述。 为了打破当前架构发展的桎梏,他们给出的答案是,需要软硬件协同设计和创新,构建领域专用架构、领域专用语言,从而构建更专业化的硬件,并提升运行速度。 作为驱动计算机架构革新的重要组成部分,编译器也在迎来它的黄金时代。就在去年4月19日的ASPLOS会议上,编译器大牛Chris Lattner在主题演讲中分享了关于编译器的发展现状和未来、编程语言、加速器和摩尔定律失效论,并且讨论业内人士如何去协同创新,推动行业发展,实现处理器运行速度的大幅提升。OneFlow社区对其演讲内容做了不改变原意的编译,希望能对AI/编译器社区有所启发。 Chris Lattner 毕业于波特兰大学的计算机科学系,具有创建和领导多个知名大型项目的经验,其中包括 LLVM、Clang、MLIR和CIRCT等编译器基础设施项目,他还带头创建了Swift编程语言。从2005年7月到2017年1月间,他曾领导苹果的开发者工具部门,随后,曾短暂领导过特斯拉的自动驾驶团队。2017年8月,Chris Lattner 在Google Brain团队领导了TensorFlow基础设施工作,包括一系列硬件支持(CPU、GPU、TPU),底层运行时和编程语言工作。 2020 年 1 月到 2022 年 1 月,Chris Lattner 在 SiFive 公司领导工程和产品团队(包括硬件、软件和平台工程),SiFive 基于开源指令集 RISC-V,向芯片设计公司提供 IP。去年 6 月,SiFive 收到了英特尔的收购意向,后者提出以超过 20 亿美元的价格收购这家公司。2022 年 1 月,Chris Lattner 和 Tim Davis 成立了 Modular AI,由Chris担任CEO,目标是重建全球 ML 基础设施。 以下为Chris Lattner演讲内容。 尽管硬件正在蓬勃发展,新加速器和新技术不断涌现,但软件业却很难真正利用它们。 为什么会这样?在加速器的世界里,比如AI和结构化计算技术发展领域,出现了标量加速和向量加速等多种层面的加速,就像CPU领域也分为标量处理器和向量处理器一样,当然现在还有多核CPU。这样一来就会出现多种硬件组合,不同的硬件安装在同一个数据中心,那这些硬件就必须相互通信。 但是,很多时候却没有一致性的内存,导致写一个C语言程序来运行所有东西是不可行的,这样的组合运行有点像超级计算机使用多个CPU一样。 同时,世界正在越来越异质化,出现了各种各样的应用。机器学习快速发展,但机器学习涉及很多技术,如果你不只研究训练和推理,还想研究强化学习,那就要了解不同的加速器。如果你想研究强化学习,就要整合主机计算和加速器计算,让它们协同工作。现在制造的很多新设备里的IP和硬件块都是可配置的,即便是随存储器层次深度改变缓存大小这么简单的事,都会影响这些设备运行所依赖的内核。 所以,尽管现在硬件越来越多样,硬件生态迅速壮大,但软件还是很难充分利用它们来提高性能。而且如果软硬件协同不到位,性能就会受到巨大影响,那不止是10%左右的浮动,比如,如果弄错了内存层次结构,性能很可能会发生断崖式下跌,变成正常水平的十分之一。 当今,加速器领域发生爆炸式增长,几乎每天都会有新公司制造新的加速器。但问题是,怎么用这个加速器?更关键的是,有人想做新应用,但他们想在软件代码库上下工夫,于是不停地推进和完善软件代码库。 你无法直接在这个新设备上使用旧的软件堆栈,它们的某个部件可能换了供应商,做了流程精简,导致所需的技术堆栈不一样。因此,你不得不给每个新的小型设备都写一个全新的软件堆栈。而这样做又导致了软件的碎片化,这种碎片化的发展带来了巨大成本,也会反噬硬件行业,因为硬件用不了了。 我的观点是,我们需要下一代编译器和编程语言来帮助解决这种碎片化。首先,计算机行业需要更好的硬件抽象,硬件抽象是允许软件创新的方式,不需要让每种不同设备变得过于专用化。 其次,我们需要支持异构计算,因为要在一个混合计算矩阵里做矩阵乘法、解码JPEG、非结构化计算等等。然后,还需要适用专门领域的语言,以及普通人也可以用的编程模型。 最后,我们也需要具备高质量、高可靠性和高延展性的架构。我很喜欢编译器,很多人根据编译器在做应用,我也很尊重这一点。可以说,他们在开发下一代神经网络,而不仅仅只想做编译器。大家可以合作,这样一来就意味着他们需要可用的环境和可用的工具。 令人兴奋的是,编译器或者编程语言工程师会迎来一个崭新的时代:过去和现在都有无数的技术诞生,这些技术正在改变世界,有幸参与这场变革浪潮非常令人激动。 接下来,我会谈谈编译器行业的早期发展,以及它带给我们的经验和对未来的启发。 当我还是学生时,编译器是单独装盒的,安装在一个软盘上,每次使用都要把软盘插进电脑里。 当时的行业状况是,不同的供应商做出不同的处理器、操作系统,都想要通过创新脱颖而出,抓住编译器的价值。这些编译器都是专用的,互不兼容,不会共享代码。所以你会看到Borland C编译器和Microsoft C编译器互相竞争,最终造成碎片化生态。这就阻碍了行业发展,但人们还没有意识到这一点。 编译器由前端、优化器和后端组成,这种固定结构已经沿用很多年了。如果一家公司自主研发了一个编译器,通常的做法是只研发一套前端和后端,而不会投入太多资金研发多种前端和后端。其他公司也会这么做,这导致不同公司的优化器和前后端不能通用。 GCC编译器团队最早打破了这种模式。GCC通过自由软件和开放许可证,允许互相合作,这使得人们可以将前端、优化器、后端分开设计,实现“关注点分离”。也因为这个原因,GCC有了多种前端和后端。 这样的“关注点分离”不但有利于编译器的研究改进,还改变了编译器的行业格局。因为GCC有最好的C++前端,所以一大批编译器工程师都在这个前端的代码库基础上改进,推动了创新和C++的发展。同时,一大批CPU公司可以直接运用GCC的前端,只需加上自己的后端就能参与市场竞争。因此20世纪90年代到21世纪初这段时间,整个行业的碎片化程度降低。从那时起,GCC为C语言编译器的发展铺平了道路,涌现出更多新编译器。这是行业的巨大成功,因为它点燃了创新的火把。 继GCC的革新之后又出现了一些新技术,其中包括我自己特别喜欢的LLVM,我想讲的是它的模块性。它颠覆了编译器长久以来的“前端+优化器+后端”的三段结构,LLVM编译器是一系列库(library)的组合。查看LLVM代码库会发现,所有代码都在lib目录下。这些库可以单独拎出来,与其他库组合、搭配使用,也可以重复使用。它可以和电影特效处理引擎、数据库查询引擎结合起来,LLVM既是一个优秀的C++编译器,也可以发挥更广泛、更有创新性的用途。 LLVM的模块性凸显了接口和组件的重要性。自LLVM诞生的20多年来,没有了前端、优化器、后端的划分,它用一种革新的方式推动了编译器行业的发展。比如可以把XA6编译器或者X86后端用到别的地方,还可以集中全世界顶尖专家来专门单独研究寄存器分配器,而不用管其他编译器组件,这样既提高了扩展性,也催生了新的合作形式。LLVM的一大优点就是可以集合更多人的力量,实现更多创新。很多基于LLVM的新前端已经诞生,而且它促进了Julia语言、数字编程、Rust和Swift语言、系统程式设计、安全编程模型等大力发展,这让人倍感兴奋。LLVM的模块性、IR的独立性、低碎片化程度也催生了多种语言。 此外,LLVM还让JIT编译(即时编译)能有更多作为。虽然JIT编译器已经是一种著名的技术,但它一开始是用在其他地方。有了LLVM以后,芯片设计、HLS工具、图形处理、都更加便捷,还促进了CUDA和GPGPU的诞生,这些都是很了不起的成就。但更重要的的是,LLVM整合了的碎片化。LLVM出现之前有很多种JIT编译器框架,但LLVM的存在,提升了JIT编译器的基线,让它迸发出更多可能,也让行业可以实现更高层次的创新。 话说回来,LLVM虽然有很多优点,但它同样存在很多问题。一开始LLVM的目标是成为一个“万能”的解决方案,但结果它好像什么也没做好。很多人不断给LLVM加一些“乱七八糟”的东西,你可以对CPU和GPU可以这么做,但对加速器来说不太行。这种胡乱做“加法”就导致不能很多好地用LLVM做并行处理优化。但我喜欢LLVM的一点是,它是一个很好的CPU后端,尽管并不能很好满足其他需求。 现在我们来到了“摩尔定律失效期”,我们可以发扬LLVM作为CPU后端的优点,但如果要探索CPU以外的功能,应该把目光放到LLVM IR之外。 Patterson和Hennessey提出过一个结论:我们来到了计算机架构的文艺复兴时代,需要把计算机行业上下游人员垂直整合起来,大家既要懂硬件,也要懂软件。他们说,因为世界变化得很快,所以思考问题时要回归第一性原理,要用新的眼光去重新看待旧事物。 接下来我会讲讲加速器的构建过程,并结合经验谈谈加速器未来可能的演变。 如果观察硬件领域,会发现专用化架构已成为一种趋势,分化出一系列的专门品类。关于这个话题,我推荐观看Mike Urbach的演讲。如果把CPU看作通用型处理器,那么当你想控制所有的门(gate)时,就需要更深的专用化和更多硬编码能力。 所以一方面CPU是通用的,不像矩阵运算加速器那么专用化。然后出现了GPGPU,很灵活,功能也很强大,但要对GPU进行编程就没那么容易了。然后针对机器学习加速又出现了TPU,可以做大矩阵乘法运算和直接卷积等操作。这些是可编程的各种“xPU”,除此之外还有FPGA(现场可编程门阵列)等固定功能硬件,你可以重新配置block之间的线路;再进一步细分的话还有ASIC,也就是可以应特定需要专门设计集成电路。 总体就这两个大类,一类是通用的、可编程的,另一类是功能比较固定的。每当我思考领域专用架构时,我的脑海里就会浮现这两大类。 上图列举了一些正在做上述硬件的公司(不完全统计),可以看到有不少都是行业巨头。每个公司研究的时候都会思考:怎么给它编程?而每个公司也会给出不同的答案。比如Google在做XLA和TensorFlow,NVIDIA在做CUDA,Intel在做oneAPI,还有很多硬件公司在做自己的硬件设计工具包等等。 问题是,每个工具针对的都是不同问题,它们不协同,也不兼容。因为它们是每个公司的小型团队自主研发的,共享的代码不多,而每个公司也都孜孜不倦地给自己的工具增加新功能,各个工具都瞬息万变,造成比较混乱的整体局面。这些工具作为行业的基本组件,却有这么多不同特点,那从行业层面应该怎么做? 其实今天的加速器遇到的问题,90年代的C语言编译器也遇到过。就像人们常说的那样,历史是一个轮回。我们见证了硬件和软件的多样性爆发,但如果想要继续发展,这种多样性就会成为阻碍。所以我们需要统一,需要一些类似GCC和LLVM这样的东西,不然都要忙着为每个特定的设备开发一个专属后端,就没时间进行前端、编程语言和模型的创新了。 业内有许多精英人才,但还不够多。假如我们能够减少碎片化,把行业整合起来,就可以促进创新,加快行业发展,持续建立技术堆栈,充分利用硬件,并以全新方式利用异构计算。接下来谈谈我对加速器发展的看法,以及发展过程中可能遇到的挑战。 加速器是什么?可以把它高度简化成两个部分,第一个是并行计算单元。因为硅本身的结构也是并行的,加速器要用到许多晶体管,也就需要很多硅来达成这种并行处理能力。 第二个部分起控制作用。它的名字不太统一,有人叫它“控制处理器(Control Processor)”,有人叫它“序列器(Sequencer)”。有人希望它小一点,所以会做状态机然后嵌入寄存器。这个部分基本上起到编排并行计算单元的作用。如果并行计算单元是一个大型矩阵乘法单元,控制处理器就会命令它执行一些宏操作,例如从这个内存区加载、执行某一操作、执行另一操作、更新SRAM等。 还有一些加速器很不一样,所以控制逻辑和计算之间的比率也各有不同。正如Patterson和Hennessy所说那样,你可以选择不同的点,但每个点都需要一定程度的编排。但人们常常忘记其他一些相关的工作,比如,你不止需要编排,还要解决启动问题,比如电源管理,还要不断调试排错。如果你想做得尽善尽美,可以对这些部件进行编程;如果你希望简单一点,可以把这些部件做得很小。 当控制处理器和并行计算单元都齐备之后,怎么给它们输入和输出信息?这时就需要一个内存接口。根据抽象等级的不同,这个内存接口可以是小型的block,也可以是支持物联网的芯片,这样加速器就可以和该芯片连接整个网络通信了。这里需要用到像AMBA或类似的技术。 你可以在更大的粒度(granularity)上构建整个 ASIC,所有的 ASIC 都在加速,在这种情况下,你可能正在与 PCI 通信,并且正在芯片外直接访问内存,但这种“我有一个控制处理器,有一个计算单元和有一个内存接口”的模型,是构建这些东西的一种非常标准的方法。 一旦这些结构问题解决了,架构师们就开始大展拳脚,但他们往往忘记还需要软件人员参与进来。 理想情况下,他们会从最基本的问题开始着手解决,但软件最终看起来像按照几个不同的层次来做。最高层次是考虑用户体验,用户如何使用?要如何围绕它构建一个应用程序? 而最低层次则是考虑控制处理器的运行,所以至少需要一个汇编器来完成要处理的控制过程。 然后写一个运行在某种主机处理器上的驱动程序来控制这个东西,控制它打开和关闭,进行加载,把程序上传到控制处理器。之后有一些工作在这些控制处理器上运行,所以这些通常被称为内核。这个模型很通用,但最终的结果是硬件变得更复杂。所以第一代协同处理器(first generation co-processor)可能很简单,但后来有人想出了这个绝妙的主意:我们想实现更多。 在这种情况下,我们想减小面积来进行加速,想做更多的AI、物理、5G或比特币等领域的任何值得加速的东西。最终的结果需要更多的控制处理器,因为光速和线延迟等问题会导致不能只用一个控制处理器在一个巨大的芯片上协调所有的晶体管,所以你需要多个控制处理器并行处理。 幸运的是,这很容易放进你的模型里,因为只需要将这些设备内核并行化、多线程化或做一些展开(tiling),只需做一些简单的改动就可以了。然后,在这些淡褐色单元上运行的内核就可以一起协作解决问题,把任何问题在空间上进行分解,再并行处理。 现在开始,事情变得更加复杂。当建立一个像GPU一样专门的加速器,比如要把数十亿个晶体管组装成一个完整的十字形芯片。这种规模的芯片会产生多方面的问题。 首先,你最终想有多层次的平铺,所以不会只想拥有492个核,你可以在GPU上有阵列,或者有不同的SMS或类似的东西。或者将有异质性介入,所以在同一物理芯片上将有不同种类的加速器,因为我可能正在做AI,但需要能够解码一些JPEG。因此,如果我打算在相机上做推理,需要对相机的传感器数据进行原始解码,这将得到新的加速器block,它们是硬编码用于不同操作,而且这些都混在一起。 然后它们需要通过内存接口相互通信,这需要对其进行编程,并且变得更加复杂。现在突然需要这个中间层的技术,在加速器上处理多个数据流时,不只是在加速器上不同单元的tile上有并行性。因为现在有多个不同的操作在同时运行,所以要解决工作负载平衡的问题。此外,还要解决通信优化问题,光速是一个痛点,因为把数据从芯片的一端传到另一端需要时间。但是这段时间你不想闲着,而是想在通信的同时进行另一个通信过程,或者在做通信的同时进行计算。 你希望能够运行像TensorFlow一样的东西,现在你可能有一个XA6后置处理器,所以希望从加速器回到主机处理器。因为你在做文件系统操作或其他非常奇怪的事情,就必须能够协调这一点,突然,这层软件开始变得非常大,而且相当复杂。 在很多情况下已经证实了这一点,很多加速器都经历过这种情况。一个问题是,他们一开始都是手工写的kernel,这些东西有多个不同的进化步骤,从这些硬件供应商的产品中可以看到:随着时间的推移,他们的硬件不断进化,变得越来越普遍,软件堆栈和支持的功能也在不断进化。 所以kernel的优点是,它是最简单好用的开始方式。一个硬件人员与一个固件人员配对,就可以清楚地知道硬件的作用。软件人员和硬件人员通过协同设计紧密合作,让你的矩阵乘法在AI工作负荷上运行得非常快。它的抽象程度很低,很容易搞定。 问题是,这并没有真正扩展能力。所以我们也看到,现在想在加速器上运行的工作负载不仅仅是矩阵乘法,他们想要在这些东西上运行成百上千种不同的核运算,涵盖从卷积和矩阵乘法到重塑(主要是内存操作)到元素间操作(element-wise operations),再到各种奇怪的操作,比如Top K和排序,再到非常普遍的新一代研究稀疏算法的东西和其他新兴的不同应用。 随之而来的问题是,一方面你有这些正在运行的kernel,另一方面,你有硬件的无限通用性。因此,在一个供应商的硬件中,也许你可以把它固定然后看看新一代的技术。 你只需要手写一百或一千单位的kernel就行了。也许这没问题,但当你推出了第二代设备,可能改变了内存层次结构,给控制处理器增加了一些新指令,增加了可选的功能,或者你决定做kernel融合,想对卷积进行元素间操作,这时你就有一个n次方的不同kernel的组合需要很好地融合。即使你有成千上万个软件工程师,你也不能手写所有的kernel,因为你希望你的硬件团队能够快速推进工作。 我见过这种情况好几次了,最终人们开始手写kernel,但后来他们写了一个Python程序来生成kernel,这些Python程序在某种意义上就像微型编译器。 如果继续这样做,这些复杂性就会叠加起来,最终形成了这个编译器层,它可以通过强大的编译器工程来形成。这在理论上是可能的,随着时间的推移,它可以通过自然演变逐渐形成,就像人类从爬行到行走一样,这是我在实践中所看到的真实情况。每个人都有机会成为这个过程的缔造者,这方面还有很大的进步空间。 当你在构建一个真实的东西时,实际上很困难。刚开始感觉容易,是因为可以构建一个小型控制处理器和小型加速器,让一些软件运行得很快,这种情况下很简单。但当你沿着“这条路”继续走,困难会慢慢出现,实际上,直到遇到扩展问题之前都不会觉到特别难,但你不想改变方向了。 此外,正如我们之前所说的,产品质量并不一直都很好。现在,人们创造出令人惊叹的产品,而我也一直对这个行业中不断发生的创新感到惊讶。 但我们也见过一些编译器崩溃了,比如技术堆栈中出现的坏消息。这是有道理的,人们就不会总在这方面投资。虽然我能理解这种做法,但这阻碍了行业发展,导致使用这些工具变得更加困难。因此,要减少社区中愿意容忍和使用这些工具的人。 我认为另一个真正的问题是,大部分复杂性真的与解决加速器问题无关。如果我想建立一个5G网络加速器,需要考虑5G、FTS、问题中固有的并行性以及如何利用它们。如果要考虑人工智能机器学习的工作量,我应该考虑的是算数运算以及计算和内存的正确比例等等。 但相反,我们通常需要在和这些重要的问题无关的事情上投入很多时间,以复杂性而告终。 如果你把与加速器有关的重要东西抹掉,剩下的就是控制处理器的内核驱动和汇编程序以及像所有这些复杂的多流管理小组,该如何利用加速器上的所有tiles。这不是我们想花费时间的地方,要花时间在编程模式、硬件等方面进行创新,但这种碎片化是真正阻碍行业发展的原因。 因此,我的主张是创新编程模型,发展新的应用程序,通过不断创新推动行业向前发展。我们应该对此过程所需的一切实行标准化,通过标准化能够快速完成工作,然后就可以把时间花在真正重要的事情上。 那么,如何做好这个工作?幸运的是,业界已经开始对我们需要的所有接口总线进行标准化。如果你与你知道的SoC结构连接,通常使用AMBA或CHAI或类似的东西。如果要和内存连接,那么你要用DDR或HBM这样的东西。如果你要在系统中建立一个插件卡,要使用像PCI Express这样的东西。有一些新的标准,如CXL定义了新的方式,可以将PCI普遍化,并允许在更大规模的系统中使用新型加速器,但我们需要更进一步。 那么,这个控制处理器呢?需要注意的是,当我们观察加速器,开发在加速器上面运行的软件最终比打造硬件的成本更高。况且在这一点上,硬件是更被人熟知的。不同硬件有不同配置,但构建软件是一个尚未解决的问题。 控制处理器也在堆栈的底部,所以当我谈到系统设计中存在这些微妙的陷阱时,事情看起来很容易,但更进一步会发现它们很困难。控制处理器是其中一种情况,刚开始,你考虑的是用小型状态机来控制它,所以我会在电子表格程序写一个编译器。 有时候要意识到需要做电源管理,还要考量安全性,需要构建和协调这些东西的困难部分,真正改变它们最终的工作方式。如果构建控制处理器的人没有同时构建编译器,那么他们就不会感受到构建软件的痛苦,而软件最终是更困难的部分。 Patterson和Hennessey在他们的演讲中谈到了这一点,他们从60年代开始观察到行业存在着巨大的碎片化。IBM最终解决这个问题的方法是标准化指令集,选择的是IBM 360指令集,至今仍在使用。这是一个惊人的壮举。 所以,我们要做出选择,比如我们是否要标准化这些控制过程。我们会使用IBM 360吗,还是我们要用一些新的东西? 我认为,我们应该使用一些新东西,有一种指令集技术叫做RISC-V,它是CPU的一个开放的行业标准。我喜欢RISC-V的原因是,它是一个模块化的指令集,就像LLVM一样是模块化的、基于库的。如果不想用浮点数,它允许把指令集的不同部分划分子集出来。 但是,如果你不想要整数乘法,也可以把它去掉。关于RISC-V的伟大之处在于,它不仅提供了一个指令集标准,还提供了在上面运行的整个软件世界。因此,你可以得到一个C语言编译器,得到Linux,得到所有围绕RISC-V的这些东西。 像SiFive这样的公司,它制造了很多不同的RISC-V处理器。你可以在设计领域中得到许多不同的视角,以不同的权衡点来实现该规范。因此,如果你正在建立一个非常简单的加速器,如矩阵乘法或卷积加速器,可以有一个非常小的RISC-V核来控制一个大的硬编码加速器block。 另一方面,如果你想要更多的可编程性,你可以改变花费在控制和并行处理上的硅的比例,并且有更多的控制逻辑,从而实现更多的可编程性和灵活性,可以调整比率。也可以反过来,并行单元是处理器的一部分,使用这个处理器时,在处理器内置一个异构计算加速器。 或者相反,你可以把这个加速器中的每一个tile视为一个很大的CPU,这样做就会得到像Graviton这样的云加速器,例如,你有一堆不同平铺的CPU,通用性和加速的功能都可以在一个指令集内处理,这就允许提升软件的生态系统。 你可能会担心,如果想构建这样一个微小的控制处理器,RISC-V会如何解决这个问题?很明显,一般的解决方案太大了。有一些非常小的RISC-V的实现,你可以得到开源的标准化的RISC-V,大约有一万五千种gates的实现,这是硅行业的美妙之处。因为有很多gates,可以不必担心在控制处理器上花费太多gates,得到最符合需求的解决方案。 一旦这样做,它改变了构建加速器的方式。以前你从选择一个控制处理器开始,然后写一个汇编程序或RISC-V给出一个汇编程序。但RISC-V不仅给出一个汇编程序,还给了一个C语言编译器和一个可以编程的IR。因此,可以针对控制处理器来生成内核。不仅可以得到C语言编译器,还可以得到模拟器和调试器。我从来没有见过其他可以为模拟器和芯片安装GDB、LLDB的加速器,这不是人们通常会投资的技术,因为它是一次性的。但是,通过建立和利用RISC-V的生态系统,你可以投资并再次构建下一个级别的技术,从而获益。 一旦做到这一点,就进入到下一层级的复杂性。做出了这个类似加速器内核编译器的东西后,就会遇到下列问题:如何进行分层并行计算?一个数据中心有很多机器,电路板上有多个芯片?每个芯片在一个ASIC中有几十个或上百个不同的加速器单元,又该如何编程? 有趣的是,虽然所有这些编译器都是不同的,但它们有很多共同的特点。比如,都有内存层次结构,都有多个不同粒度级别的tiling,都需要能够与其互动。所以,尽管这些编译器是不同的,例如一个5G基站的编译器应该与AI加速器不同,但像平铺和内存层次结构这种需要解决的技术问题都是一致的。 现在有一种相对较新的编译器技术MLIR可以帮上忙。你可以把MLIR看作是一个元编译器,它允许你非常快速地构建加速器/编译器。MLIR的全称是“多级中间表示”,它支持构建分层编译器,并以适用专门领域的方式构建,同时保留领域的复杂性。然后,使用MLIR提供的大量库和例程来做一些事情,比如,用多面体编译器来做循环展开和循环融合等等。 所以MLIR是LLVM技术家族的一部分,它继承了LLVM的设计方法和使LLVM如此伟大的理念,所以有了模块化、可扩展性,有一个由友好的人们组成的伟大社区。我认为,LLVM社区的一件令人欣赏事是:LLVM是模块化的,有相当好的文档,很容易学习,适合用于研究。 我很高兴看到MLIR的出现。尽管它只有几年的历史,但它已经被广泛用于从CPU代码生成到GPU、机器学习、FPGAs以及硬件等领域,此外,也用于量子计算和编译器本身的MLIR优化模式应用。在MLIR这个领域有很多有趣的事情发生。 MLIR的另一个优点是,直接在LLVM的基础上分层。它使用LLVM的库,所以可以做即时编译,写内核然后编译成LLVM IR也很容易。当然,LLVM也有很好的RISC-V代码生成支持。你可以用一种非常简单、漂亮且可组合的方式构建基于RISC-V的加速器。 现在,我们开始看到的是,MLIR开始统一异构计算的世界,这也是我希望看到的。所有的大公司现在都在不同程度地使用MLIR,我认为,建立在RISC-V之上的MLIR很有必要,因为一旦开始从下往上整合行业,就可以开始把越来越多的层(layer)拉到一起,重复使用更多的技术。这使得我们可以专注在堆栈中更有趣的部分,而不是一遍又一遍地重新发明轮子。 我们能从中得到什么?如果我们能把稀缺的编译器和编程语言的能量整合到一起,让这些人一起工作,那么这个行业可以取得更多成就。如果我们一而再、再而三地重新发明轮子,我们就会互相拉扯。作为一个产业,我们需要的是更多的创新,更多的编程模型,更多的技术和基础设施,真的要减少行业的碎片化,提高其他未解决事物的模块化,然后专注于真正重要的部分。 我刚刚一直在谈论加速器,谈到了从CPU到TPU和GPU等各种不同的“xPU”。 硬件本身呢?上图右边留出了一个很大的灰色区域,在这个领域工作的人都是“硬件人员”,在左边领域工作的人既是硬件也是软件人员,但右边确实是一个非常不同硬件世界。 这也是并行计算单元里的东西。这就是Patterson和Hennessey谈到的适用专门领域的架构,以及如何构建这些硬件块。我们需要算法创新,需要许多不同技术的创新,这些都需要基于特定领域。 也许你不会感到惊讶,但我认为答案是编译器,这是真正要走的一条路。 作为编译器编程语言从业者,我认为硬件设计这个领域已经到了重新评估的地步。整个领域是建立在两种技术之上,但实际上主要是一种叫做Verilog的技术,你大概率可能不喜欢Verilog。它有一个非常复杂的标准,当我看它时,不知道它是被设计成一个IR,也即一个不同工具之间的中间表示,还是被设计成让人们直接书写的东西。我认为,它在这两方面都很失败,它真的很难使用,对工具来说也很难生成。 此外,EDA工具、硬件设计工具已经非常成熟,它们非常标准化,有很多大公司正在推动和开发这些工具。但他们的创新速度并不快,设计时并不注重可用性。它们比加速器编译器要差得多,绝对不是以软件架构的最佳实践来构建的,而且成本也非常高。因此,这个领域有巨大的创新机会。 我不是第一个认识到这一点的人。在开源社区,已经构建了一堆工具推动行业向前发展。这些工具非常棒,比如Verilator被广泛使用,Yosys是另一个非常棒的工具,它有很好的定理证明器(Theorem Prover)。 我的担忧在于,这些工具的理想目标是试图像专有工具一样好,而我并不真的认为专有工具有那么好。另外,这些工具的设计者并没有合作。每个工具都在遵循单一僵化的方法,没有实现大程度的模块化或重复使用,可以从其中一些工具中得到网络列表,用它来解析一些Verilog之类的东西。但是,它不是由基于库的设计构建,与LLVM之类的东西不一样。 好消息是,我看到了这里正在发生的不同进展的全面爆发,这与我们一直在谈论的摩尔定律的失效非常相关。我们看到,研究小组正在推动新硬件设计模型的生产,有Bluespec和Chisel等东西。有许多新的不同研究小组在探索不同的硬件设计方法,而且他们最终往往会生成Verilog,这真的很好,因为现在你可以从软件和硬件世界引入新的类型系统方法、编程语言思想、编译器技术。实际上,软件和硬件有很多想法是互通的。 只是软、硬件领域用不同的方式说着不同的语言。因此,如果双方能有更多的交集,这对两个行业都有益,这种合作令人惊奇,但他们也遇到了困难,这又回到了这个问题上:Verilog实际上不是一个很好的IR。 要创建在语法上正确,并且能表达你想要的东西的Verilog非常困难。此外,因为许多与Verilog有关的工具都有点奇怪,而且很难高质量地预测。生成与工具兼容的Verilog是每个前端工具都必须重新发明的一门黑科技。因此,在堆栈中真的缺失了一种组件,这个组件允许人们在编程模型水平上进行创新,并允许人们找到方法让所有工具都接受它。 有一个叫CIRCT的新开源项目正试图解决这个问题。CIRCT的全称是"Circuit IR for Compilers and Tools(编译器和工具的Circuit IR)",它构建在MLIR和LLVM之上。CIRCT社区的目的是提升整个硬件设计世界,促进编程模型的创新,并启用一套新的模块化硬件设计工具。它确实运用了很多我们到目前为止一直在讨论的基于库的技术。 此外,它提供了一个可组合的基于库的工具链,可以建立有趣的新的弹性接口连接,你可以建立Chisel社区正在探索的新编程模型,用它来加速Chisel流程。它带来了很多好处,可以让很多人一起工作,推动不同方式的创新。我们正在建立一个真正伟大的小世界,让关心硬件编译器的人在一起工作,这很有趣。这项工作仍处于早期,目标是更快地构建加速器,让加速器变得更快。 我们的大目标是,要把硬件设计和验证过程速度都提高10倍。因此,构建新硬件往往最终需要更多的成本来验证其正确性,这包括形式化方法,相当于单元测试,有很多不同方式可以证明你正在构建的东西在所有情况下都是正确的。 这种正确性验证在硬件领域比在软件领域里更复杂,因为硬件领域并没有真正的类型系统,也没有真正的多层次的IR,所以也就不允许将一个状态机表示为一个状态机,并针对它编写证明。现在,正在发生的事情是整个领域被“去掉了糖分(de-sugared)”,变成了基本上没有类型的bits,然后所有的分析和工具都在这个层面上工作,我认为,我们可以通过构建和引入编译器和语言社区中相当知名的技术来迅速提升改善整个领域。 因此,我希望我们将能够帮助覆盖整个软件和硬件领域,组合这些标准的开放工具,包括作为指令集的RISC-V,作为编译器堆栈的MLIR,以及作为关注硬件的应用的CIRCT。我们正在努力推动整个行业更快发展。 最后,我想说现在的确是“编译器的黄金时代”。我认为,随着硬件和软件的协同设计变得更加重要,我们需要比以往更快地推动创新。 编译器、编程语言以及所有的技术,包括形式化方法和提升线性类型的类型系统,以及其他相当好理解的系统,将会使整个领域受益。我认为形式化、工程化以及这个领域的不同部分的合作,都将推动所有事情发展得更快、更进一步。我很高兴看到许多学术界相当知名的方法和技术正在落地。 人们正在试图弄清楚这一点,他们学习新东西,但也在一些愚蠢的问题上翻跟头。现在的情况是,我们看到发展速度加快了,看到了新的种类创新,我们看到对旧事物有新研究,因为人们正在回到第一性原则看问题。我非常高兴和兴奋地看到所发生的这一切。 (本文已获取编译授权,视频链接:https://www.youtube.com/watch?v=4HgShra-KnY) 其他人都在看 欢迎下载体验OneFlow v0.7.0最新版本:















创客课程开发的每个主题课程需要基于现实情景,设置学习探究任务,通过问题研究、任务...
创客空间建设 能够给人们分享各种乐趣,通过电脑,技术,科学,艺术结合,设计创造一...
在了解创客教育之前,我们首先了解下何为创客。创客是一群喜欢或享受创新的人。创客跨...
STEAM教育是对传统教育的提升,它是基于自然学校方式的功能性框架,可以适合各类...