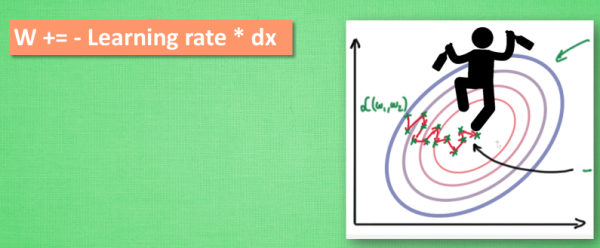
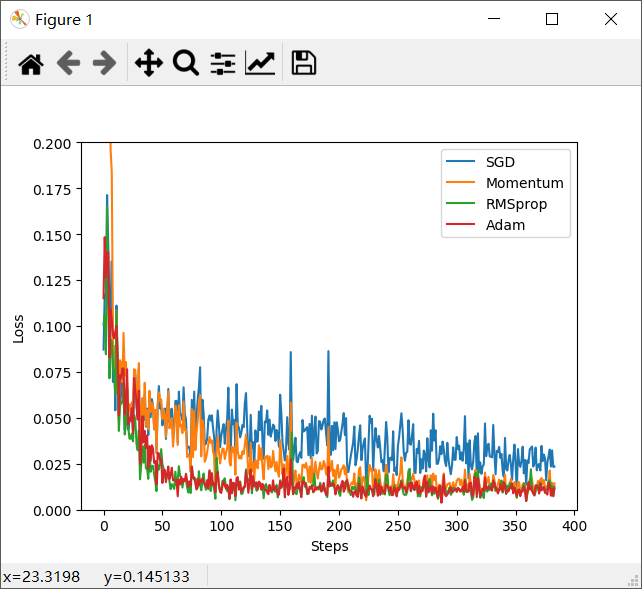
越复杂的神经网络 , 越多的数据 , 使得在训练神经网络时花费的时间也就越多。 原因很简单, 是因为计算量太大了,所以我们需要寻找一些方法, 让神经网络的训练快起来。 把数据分成小批小批的,然后再分批进行计算。每次使用批数据,虽然不能反映整体数据的情况,但是也可以很大的程度的加速训练过程,并且不会丢失过多的准确率。 合并【部分的 Momentum 的惯性原则】以及 【AdaGrad 的对错误方向的阻力】,让其同时具备两种方法的优势。 计算m 时有 momentum 下坡的属性, 计算 v 时有 adagrad 阻力的属性, 然后再更新参数时 把 m 和 V 都考虑进去。实验证明, 大多数使用 Adam 都能又快又好的达到目标, 迅速收敛。 上面已经介绍了几种优化器,那么我们现在编写代码来看一下各种优化器的效果图 输出结果: 为了更好的对比出每一种优化器,需要给他们各自创建一个神经网络。 创建不同的优化器,用来训练不同的网络。 输出结果: 2)图示,四种优化器的对比图1、Stochastic Gradient Descent (SGD)
2、Momentum 更新方法

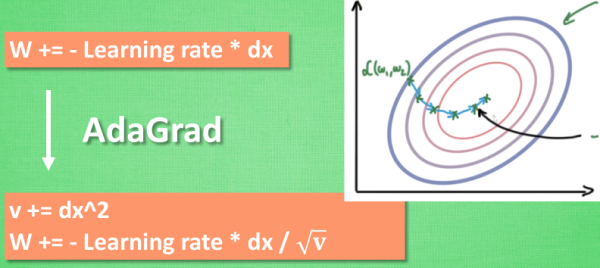
3、AdaGrad 更新方法
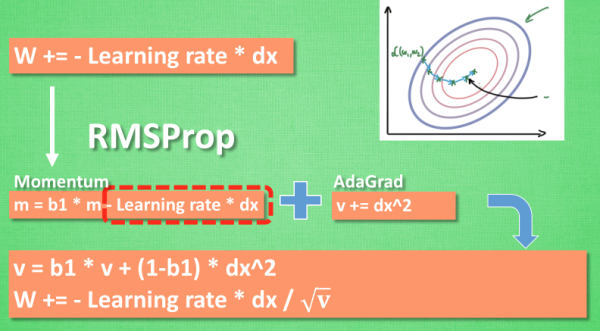
4、RMSProp 更新方法
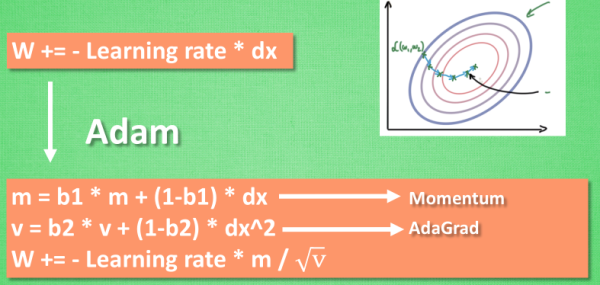
5、Adam 更新方法
1、准备伪数据

2、创建神经网络
3、优化器 Optimizer
4、训练
5、代码整合
1)会输出轮数0-11。
创客课程开发的每个主题课程需要基于现实情景,设置学习探究任务,通过问题研究、任务...
创客空间建设 能够给人们分享各种乐趣,通过电脑,技术,科学,艺术结合,设计创造一...
在了解创客教育之前,我们首先了解下何为创客。创客是一群喜欢或享受创新的人。创客跨...
STEAM教育是对传统教育的提升,它是基于自然学校方式的功能性框架,可以适合各类...