在机器学习中,最简单就是没有任何优化的梯度下降(GD,Gradient Descent),我们每一次循环都是对整个训练集进行学习,这叫做批量梯度下降(Batch Gradient Descent),我们之前说过了最核心的参数更新的公式,这里我们再来看一下: 由梯度下降算法演变来的还有随机梯度下降(SGD)算法和小批量梯度下降算法. SGD:每次迭代只使用一个样本(每个小批量(mini-batch)仅有1),优点是当训练集较大时,随机梯度下降可以更快,但是参数会向最小值摆动,而不是平稳地收敛。 说到这里要提到一点,到此为止,我们看到第梯度下降曲线都是波动的。产生下降波动的原因是每一个bach-size都是一个局部数据集的参数更新,而非像整体梯度下降一样总体平缓下降。 需要注意的是速度v是用0来初始化的,因此,该算法需要经过几次迭代才能把速度提升上来并开始跨越更大步伐。当beta=0时,该算法相当于是没有使用momentum算法的标准的梯度下降算法。当beta越大的时候,说明平滑的作用越明显。通常0.9是比较合适的值。那如何才能在开始的时候就保持很快的速度向最小误差那里前进呢? 这里提到了Adam算法,以及为什么Adam算法被大众青睐。
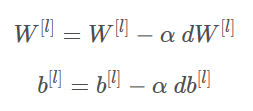
l是指当前的层数
α是学习率
如图: 不过在我们日常使用中,用到更多的是小批量(mini-batch)梯度下降法。
不过在我们日常使用中,用到更多的是小批量(mini-batch)梯度下降法。
小批量梯度下降法是一种综合了梯度下降法和随机梯度下降法的方法,在它的每次迭代中,把所有的数据集分割为一小块一小块的来学习,它会随机选择一小块(mini-batch),块大小一般为2的n次方倍。这样的好处是可以充分发挥GPU的性能缩短时间,如图:
 也就是说小批量梯度下降是SGD,和常规梯度下降的融合版本。继承了两者的优点。
也就是说小批量梯度下降是SGD,和常规梯度下降的融合版本。继承了两者的优点。
为了减小此类上下波动,大佬们提出了一个概念,叫做动量。你可以抽象理解为拿着皮鞭赶马车,让马儿快点到达目的地。
我们将把以前梯度的方向存储在变量v中,从形式上讲,这将是前面的梯度的指数加权平均值。
我们要影响梯度的方向,而梯度需要使用到dW和db,那么我们就要建立一个和dW和db相同结构的变量来影响他们。上公式:
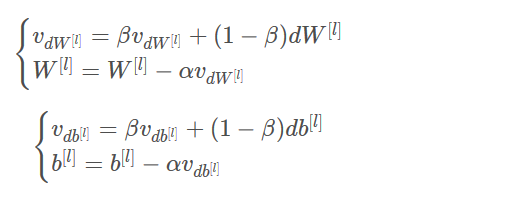
其中:
l是当前神经网络的层数
β是动量,是一个实数
α是学习率
Adam:
1. 计算以前的梯度的指数加权平均值,并将其存储在变量v(偏差校正前)和vcorrected(偏差校正后)中。
2. 计算以前梯度的平方的指数加权平均值,并将其存储在变量s(偏差校正前)和scorrected(偏差校正后)中。
3. 根据1和2更新参数。
 t :当前迭代的次数
t :当前迭代的次数
l:当前神经网络的层数
β1? 和 β2?:控制两个指数加权平均值的超参数
α :学习率
ε:一个非常小的数,用于避免除零操作,一般为1的负八次方
创客课程开发的每个主题课程需要基于现实情景,设置学习探究任务,通过问题研究、任务...
创客空间建设 能够给人们分享各种乐趣,通过电脑,技术,科学,艺术结合,设计创造一...
在了解创客教育之前,我们首先了解下何为创客。创客是一群喜欢或享受创新的人。创客跨...
STEAM教育是对传统教育的提升,它是基于自然学校方式的功能性框架,可以适合各类...