关于文中所涉及的式16的疑问,后续我又进行了推导和简单证明,发现确实没问题是自己矩阵论的知识基础太差了…… 经过推导,不太明确的地方是红线标注的两项似乎并不能直接合并同类项。通过判断这两项应该是互为转置的,如果按照式16中所给的可以合并,则意味着这两项均为对称矩阵,那么如何证明呢? 问题解决! 约束是MPC和标准的线性二次(LQ)控制的区别所在。 针对线性二次型问题,代价函数通常如下设计: 初始状态可以通过测量获得,而状态轨迹的剩余序列则是由模型和控制输入序列u决定的。通过上式不难发现,MPC的代价函数显示地依赖于控制输入序列及初始状态。控制器的可调参数是矩阵Q和R。通常我们允许终态有不同的权重矩阵 求解最优LQ控制问题即解决: 使得代价函数最小的控制序列。在实际应用中通常 针对多级优化函数问题,其代价函数通常有如下的特殊结构: 同理求解多级优化问题即解决: 我们可以观察到代价函数的特殊之处在于每一部分代价仅与一个变量对有关,且同一变量仅作用于相邻的代价子函数。所以求解可以分级进行: 这种解法是不是似曾相识——没错就是大热的动态规划(dynamic programming,DP)解法。我们按照与其出现次序相反的顺序求解符合要求的解变量,这种解法被称作反向动态规划(backward DP)。嵌套式的解法让人很自然地联想到了内外环控制。 那么是否可以使用动态规划的方法来求解线性二次最优化问题呢?答案是必然的。 令 终态为: 那么线性二次代价函数可以重写为: 由于 式中有如下关系存在: 利用反向DP方法,首先要从最末状态(红框标记)着手开始计算。 其中: 之所以将最末时刻的代价函数写为上式形式,可以很明确的看出,使得当前时刻代价最小的 这里有一个误区,在式15中我们在计算最末状态时可以通过设计合适的矩阵 将式16中的其他式子带入可得式17。至此 不难发现此时的子代价函数与式12结构相似,解法同理: 从 终止条件为 通过迭代求解即可得到需要的控制输入序列。 本文其实是作者在阅读《Model Predictive Control-Theory and Design》的一些思考和记录,在此与大家分享,新人基础薄弱难免有谬误,欢迎各路大神批评指正!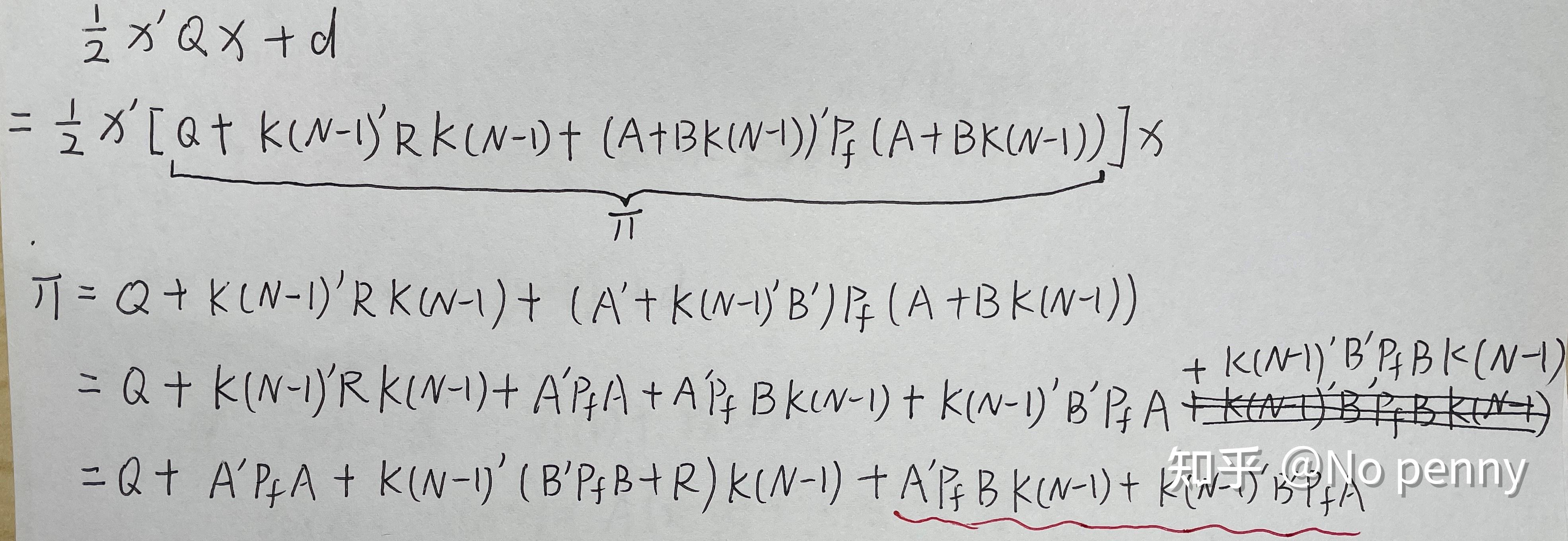

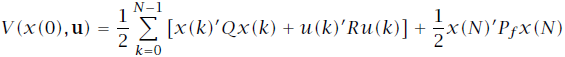
。如果Q比R大,则系统会采用更小的控制动作驱动状态回到原点(目标点)。如何选择这两个矩阵的参数就是LQ控制在工业领域应用时面对的挑战之一。由于使用相同的目标函数,MPC面临相同的挑战。
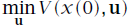
都会假设为对角阵。在此,并不作如上假设,认为其均为实对称矩阵,
为半正定矩阵,
为正定矩阵。(为什么作出如上假设呢?)当如上假设成立时,最优控制问题的解唯一存在。
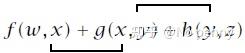
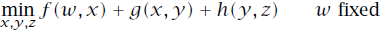
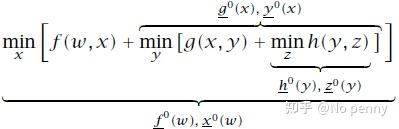
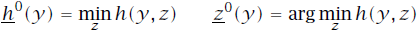
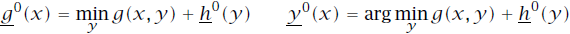
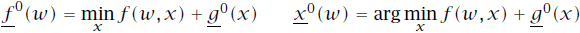
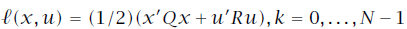
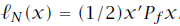
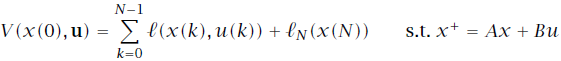
已知所以选用反向DP算法来求解问题。
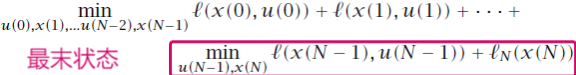
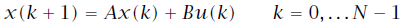
、
、
分别表示最优代价、最优决策\\最优决策对(因为最优决策变量是由后两者同时决定的)。按照反向DP算法,当前时刻的状态由之前的最优变量显式影响。表现为下式:
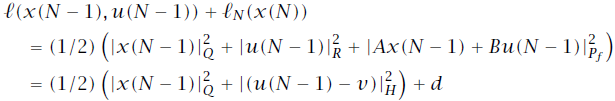

的取值是
,此时代价函数的值仅与前一时刻的状态值
相关。通过设计合适的矩阵
可以保证代价函数最小值为
。将上述结论进行总结,推广到所有的
。

从而实现令代价函数到达最小值
,但是在迭代的过程中通
不能保证每个状态下代价函数的最小值均为
,而是
。在式16中红框标注的部分,在我尝试推导时存在一些问题,涉及该式中一些元素的转置,这里似乎直接将两项进行了合并,但是我没有找到两项相等的证据。
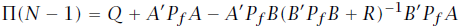
的最小值为仅与
相关。利用该函数可以应用反向DP方法进行迭代,反向向前则下一个阶段的代价函数优化为:
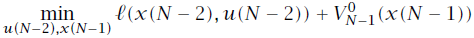

到
的迭代就是我们熟知的反向黎卡提迭代过程,可以总结为下式:
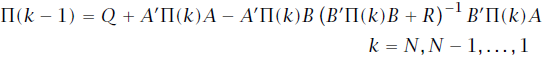
。由于迭代是反向的,这里的终止条件其实相当于初始条件。剩余的变量的迭代公式同理可以由式16及式19总结得出:
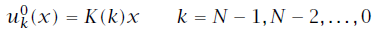
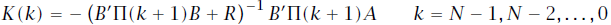
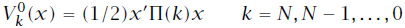
创客课程开发的每个主题课程需要基于现实情景,设置学习探究任务,通过问题研究、任务...
创客空间建设 能够给人们分享各种乐趣,通过电脑,技术,科学,艺术结合,设计创造一...
在了解创客教育之前,我们首先了解下何为创客。创客是一群喜欢或享受创新的人。创客跨...
STEAM教育是对传统教育的提升,它是基于自然学校方式的功能性框架,可以适合各类...