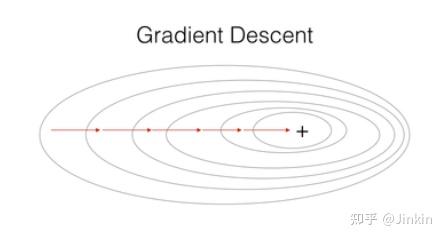
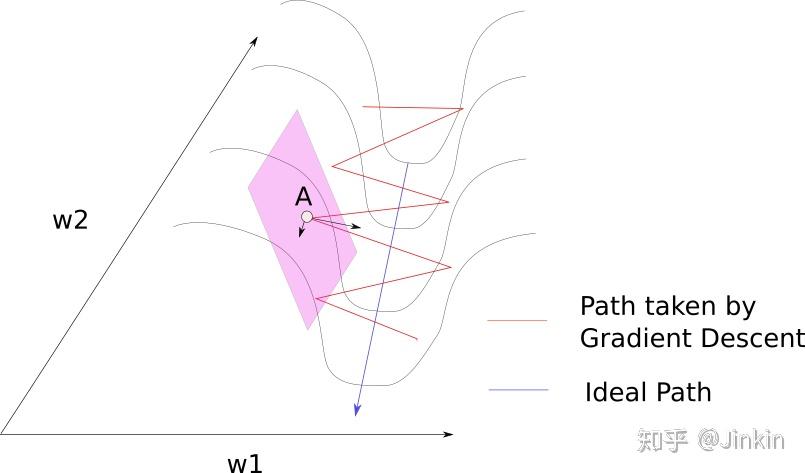
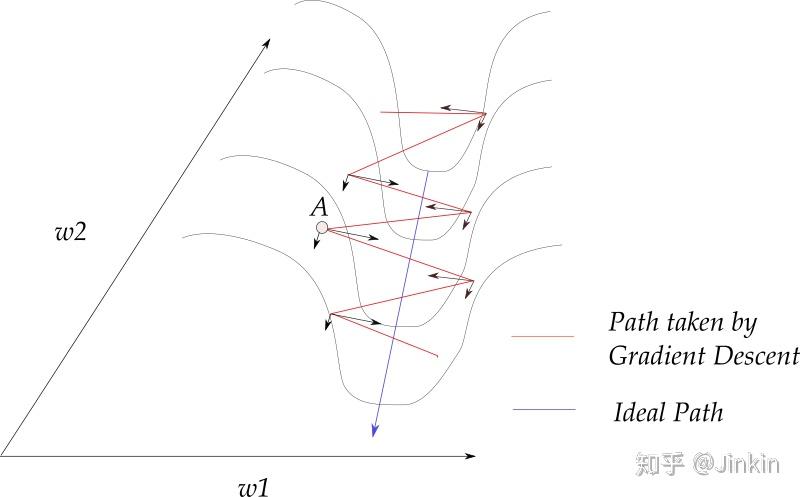
不管是momentum, RmsProp还是adam, 其核心算法都是梯度下降, 都是在SGD的基础上加上了不同的learning rate scheduler而已。上图用3-D图来描述梯度下降,x轴和y轴分别描述两个权重参数w1和w2,而z轴描述损失,曲面上的一点(x,y,z)就表示在w1=x,w2=y时,loss=z。注意,在上图情况下,梯度下降完全不涉及z方向的移动,这是因为只有权值w1和w2是自由参数, 它们分别由x和y描述。实际的轨迹在x-y平面上投影出来是一条直线(或者曲线)。类似于下图,椭圆为等高线,轨迹的投影就是直线(或者曲线)。 RMSProp, Momentum, Adam等算法都是在传统的SGD算法上衍生出来的,它们都是为解决SGD在优化时所存在的一些问题而诞生的。这里首先指出SGD优化时容易出现的问题: 考虑当前我们处于点A,我们执行梯度下降策略时会求出它在点A的梯度,由于事实上轨迹只涉及到w1-w2平面的移动,我们就将梯度沿w1和w2分解,得到两个分量,如果这时候发现梯度沿w2方向的分量非常小,而沿w1方向的分量非常大,那么就会出现一个问题,我们的算法会一直像图中红线那样震荡,而不会像蓝线这样走向最优(w越小越优),并且还会长时间徘徊在半山腰,不会走到蓝线所在的低谷。如此看来,震荡大大减慢了我们网络的收敛速度. 为了解决这个震荡的问题,加快收敛速度,人们提出了RMSProp、Adam、Momentum等一系列优化算法,它们都从不同角度解决了这个问题。 执行SGD时一个很常用的技巧就是Momentum,Momentum巧妙地利用了梯度的历史信息,来减缓SGD执行时容易出现的震荡的情况。摆上公式: 式子中第一项 我们发现,对于上图的震荡的情况,w1方向上的各个历史梯度分量几乎都是相反的(一左一右一左一右这样......),我们就很容易观察到一个规律,如果某一个方向容易产生震荡,那么这个方向上的各个历史梯度分量通常都是相反的(一左一右)。如果我们将这些梯度矢量相加,w1方向上的梯度分量几乎就能约掉了,这样就减缓震荡。而在w2方向(即非震荡的方向),历史梯度基本上都是同向的,这样这个方向上的梯度分量在加和之后会更大一些,收敛得更快了。momentum就是这样减缓了震荡,并加速了收敛。 momentum减缓震荡的方式是通过矢量加和约掉震荡方向上的梯度分量。 RMSProp则换了一个角度,通过动态地调整学习率来避免震荡,直观来说,对于上面那张图,我们可以通过减小震荡方向上的学习率来避免震荡。RMSProp自动化了这个过程。摆上公式: 第一个公式:计算梯度的指数平均(exponential average)。这一点仍是仿照momentum的。因为momentum的滑动平均就和这个长得很像。他们都对最近时间的梯度予以较大的权重,对较远时间的梯度较小的权重。在momentum中,w1上的分量被抵消了,但在RMSProp中,w1方向上的分量由于进行了平方计算,它们加和反而变得更大了。 第二个公式:计算更新量。从上面我们知道,w1方向上的 RMSProp有点模拟退火那意思,它会在训练过程中自动调整学习步长,如果某方向上的梯度过大,那么RMSProp就会通过减缓该方向上的学习率来平稳更新。 结合了RMSProp和Momentum算法,上公式: 前面提到,momentum减缓震荡的方式是通过矢量加和约掉震荡方向上的梯度分量。也就是Adam这里第1个公式计算的 综上,虽然这些算法看起来很高大上,但是事实上都只是SGD带不同的learning rate scheduler,简化了SGD的调参过程而已。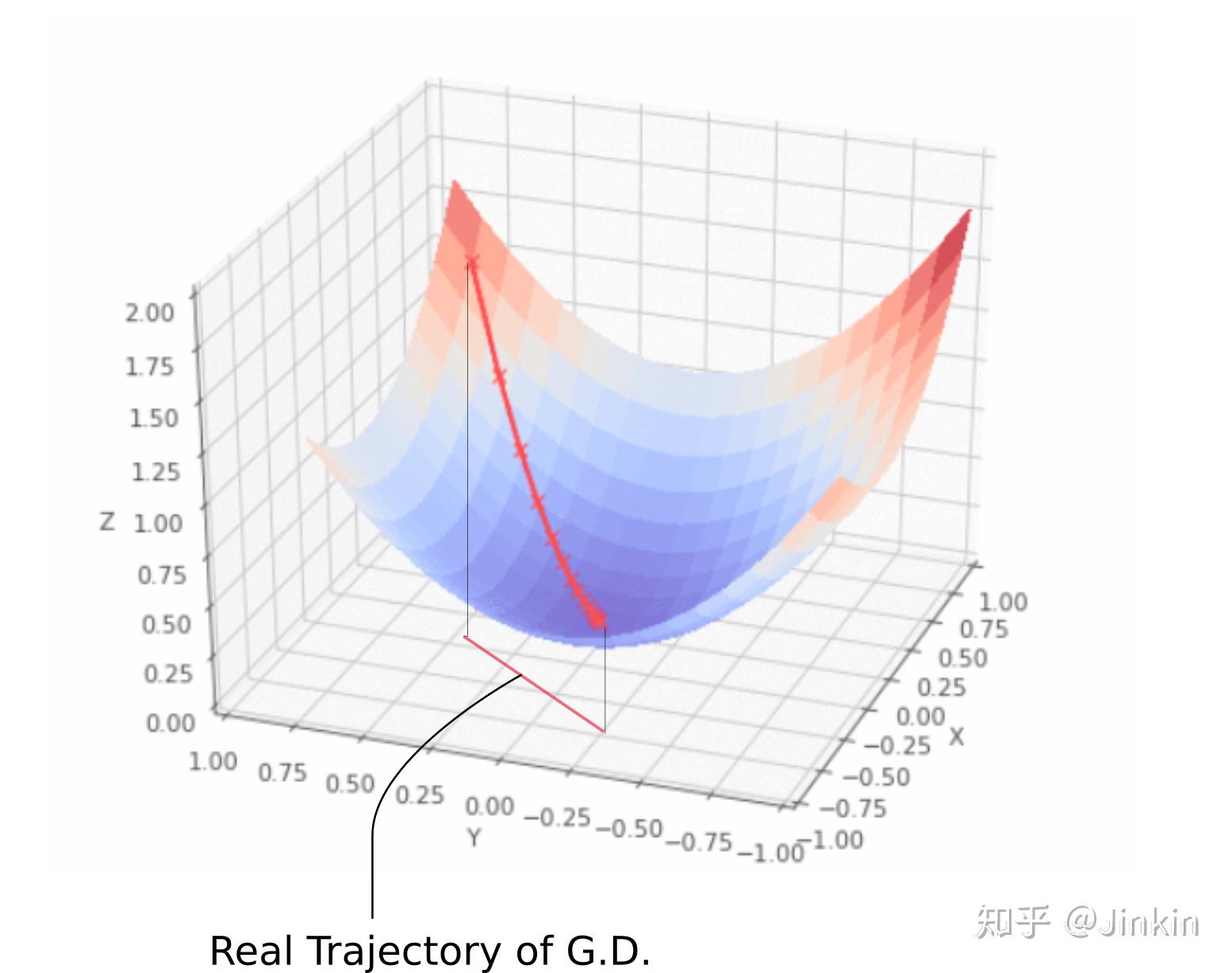
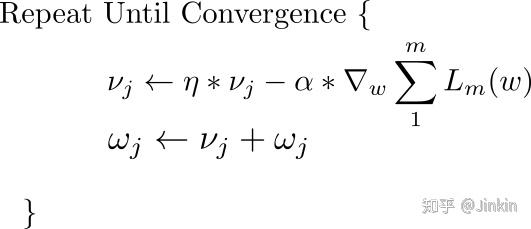
就是历史梯度的加权累积量,而
就是我们当前时刻计算的梯度和它的系数
。从公式上看,momentum就是对梯度做了一个滑动平均,即将历史梯度通过加和的方式给考虑了进来。但加和为什么有效呢?为什么能够减缓震荡呢?上图:

较大,那么计算后的学习率就会较小,而w2方向上的
更小一点,计算后的学习率比起w1来说就会稍大一些。这样,就抑制了w1方向上的震荡。

(又称一阶动量)干的事儿。RMSProp通过动态地调整学习率来避免震荡,也就是Adam这里第2个公式计算的
(又称二阶动量)干的事儿。所以Adam这里直接粗暴地综合了前两者的优点。
创客课程开发的每个主题课程需要基于现实情景,设置学习探究任务,通过问题研究、任务...
创客空间建设 能够给人们分享各种乐趣,通过电脑,技术,科学,艺术结合,设计创造一...
在了解创客教育之前,我们首先了解下何为创客。创客是一群喜欢或享受创新的人。创客跨...
STEAM教育是对传统教育的提升,它是基于自然学校方式的功能性框架,可以适合各类...